本文发表于一年多前。旧文章可能包含过时内容。请检查页面中的信息自发布以来是否已变得不正确。
介绍资源管理工作组
我们为什么在这里?
Kubernetes 已发展到支持多样化且日益复杂的应用程序类别。我们可以部署和扩展基于微服务的现代云原生 Web 应用程序、批处理作业以及具有持久存储需求的状态有状态应用程序。
然而,Kubernetes 仍有机会改进;例如,运行需要专用硬件或在考虑硬件拓扑时性能明显更好的工作负载的能力。这些冲突可能使应用程序类别(特别是在成熟的垂直领域)难以采用 Kubernetes。
我们在此看到了前所未有的机会,如果错失,代价将是巨大的。Kubernetes 生态系统必须通过有意义地满足尚未服务的的需求,为下一代系统架构创造一条可消费的前进道路。资源管理工作组与其他 SIGs 一道,必须展示客户希望看到的愿景,同时使解决方案能够在一个完全集成、精心规划的端到端堆栈中良好运行。
当某个特定挑战需要跨 SIG 协作时,就会创建 Kubernetes 工作组。例如,资源管理工作组主要与 sig-node 和 sig-scheduling 合作,以推动 Kubernetes 中对额外资源管理功能的支持。我们确保经常咨询来自不同 SIGs 的关键贡献者,因为工作组无意代表任何 SIG 做出系统级决策。
其中一个例子和关键优势是工作组与 sig-node 的关系。我们能够确保在考虑功能设计之前完成几个版本的节点可靠性工作(在 1.6 中完成)。这些设计是使用案例驱动的:研究各种工作负载的技术要求,然后根据对最大横截面的可衡量影响进行排序。
目标工作负载和用例
工作组的关键设计原则之一是用户体验必须保持简洁和可移植,同时仍能展现业务和应用程序所需的基础设施能力。
虽然不代表任何承诺,但我们希望 Kubernetes 最终能够优化运行金融服务工作负载、机器学习/训练、网格调度器、MapReduce、动画工作负载等。作为一个用例驱动的团队,我们考虑潜在的应用程序集成,这也可以促进一个互补的独立软件供应商生态系统在 Kubernetes 之上蓬勃发展。
为什么这样做?
Kubernetes 很好地涵盖了通用 Web 托管功能,那么为什么还要费力扩展 Kubernetes 的工作负载覆盖范围呢?事实是,目前 Kubernetes 优雅地涵盖的工作负载只占全球计算使用量的一小部分。我们有一个巨大的机会,可以安全、有条不紊地扩展可以在 Kubernetes 上优化运行的工作负载集。
迄今为止,在扩展工作负载覆盖范围方面已取得显著进展:
- 有状态应用程序,例如 Zookeeper、etcd、MySQL、Cassandra、ElasticSearch
- 作业,例如处理当日日志或任何其他批处理的定时事件
- 通过 Alpha GPU 支持加速机器学习和计算密集型工作负载。总的来说,参与 Kubernetes 工作的人员正从客户那里听到我们需要走得更远。在 2014 年容器获得了巨大的普及之后,业界围绕着更现代的、基于容器的数据中心级工作负载编排器展开了讨论,因为人们都在规划他们的下一个架构。
因此,我们开始倡导扩大 Kubernetes 的工作负载范围,从整体概念到具体功能。我们的目标是把控制权和选择权交给用户,帮助他们自信地走向他们选择的任何基础设施策略。在这种倡导中,我们很快发现了一大批志同道合的公司,他们对拓宽 Kubernetes 可以编排的工作负载类型感兴趣。因此,工作组应运而生。
资源管理工作组的诞生
在 2016 年 Kubernetes 开发者峰会(在 CloudNativeCon | KubeCon Seattle 之后)期间进行了广泛的开发/功能讨论后,我们决定正式成立我们这个松散的组织。2017 年 1 月,Kubernetes 资源管理工作组成立。该小组(由 Red Hat 的 Derek Carr 和 Google 的 Vishnu Kannan 领导)最初被定位为一项临时倡议,主要为 sig-node 和 sig-scheduling 提供指导。然而,由于工作组内部目标的交叉性以及快速发现的路线图的深度,资源管理工作组在最初几个月内成为了一个独立的实体。
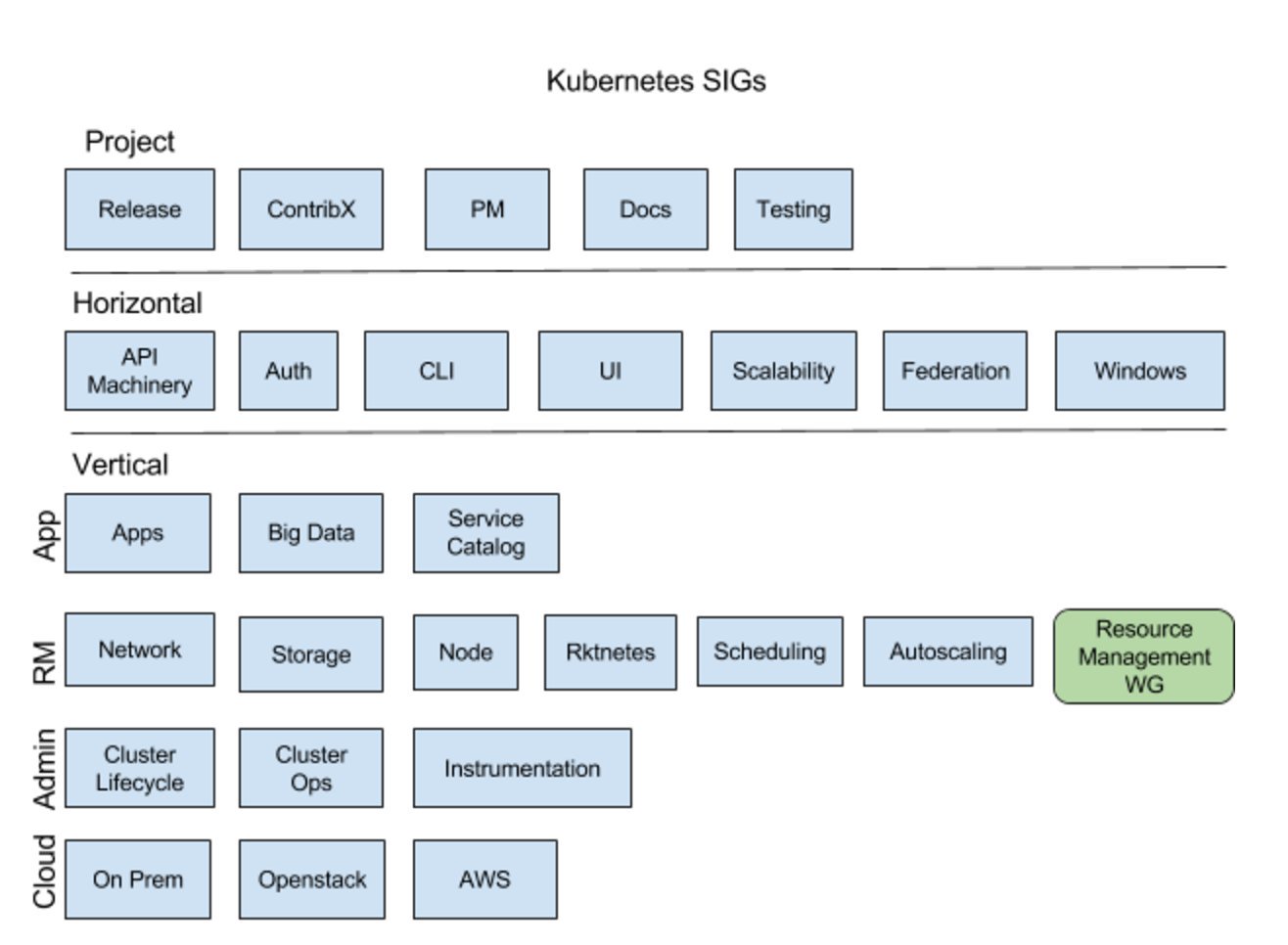
最近,Google 的 Brian Grant (@bgrant0607) 在他的 Twitter 动态上发布了以下图片。这张图片有助于解释每个 SIG 的作用,并展示了资源管理工作组在整个项目组织中的位置。
为了帮助启动这项工作,资源管理工作组于 2017 年 5 月举行了首次面对面启动会议。感谢 Google 承办!

来自 Intel、NVIDIA、Google、IBM、Red Hat 和 Microsoft(以及其他公司)的人员参加了会议。
您可以在此处阅读那次为期 3 天的会议的成果。
资源管理工作组的章程中列出的、旨在增加 Kubernetes 工作负载覆盖范围的优先功能列表包括:
- 支持性能敏感型工作负载(独占核心、CPU 绑定策略、NUMA)
- 集成新的硬件设备(GPU、FPGA、Infiniband 等)
- 改进资源隔离(本地存储、大页、缓存等)
- 提高服务质量 (性能 SLO)
- 性能基准测试
- 与上述功能相关的 API 和扩展。讨论清楚地表明,各种工作负载的需求之间存在巨大的重叠,我们应该消除重复需求,并进行通用化处理。
工作负载特征
最初目标的一组用例具有以下一个或多个特征:
- 确定性性能(解决长尾延迟)
- 单个节点内以及共享控制平面的节点组内的隔离
- 对高级硬件和/或软件能力的要求
- 可预测、可重现的放置:应用程序需要围绕放置提供细粒度保证。资源管理工作组正在主导这些工作负载功能的设计和开发。我们的目标是为这些场景提供最佳实践和模式。
初始范围
在最近面对面会议之前的几个月里,我们讨论了如何安全地抽象资源,以保持可移植性和简洁的用户体验,同时仍能满足应用程序需求。工作组最终制定了一个多版本路线图,其中包括四个短期到中期目标,这些目标在目标工作负载之间有很大的重叠:
- Kubernetes 应提供对 NIC、GPU、FPGA、Infiniband 等硬件设备的访问。
- Kubernetes 应该提供一种方式,让用户通过 Guaranteed QoS 层请求静态 CPU 分配。此阶段不支持 NUMA。
- Kubernetes 应该提供一种方式,让用户可以使用任意大小的巨页。
- Kubernetes 应该为 CPU 和内存以外的设备实现一个抽象层(类似于 StorageClasses),允许用户以可移植的方式使用资源。例如,Pod 如何请求具有最小内存量的 GPU?
参与和总结
我们的章程文件包含一个联系我们部分,其中包含指向我们的邮件列表、Slack 频道和 Zoom 会议的链接。以前会议的录音已上传到 Youtube。我们计划在奥斯汀举行的 CloudNativeCon | KubeCon 2017 Kubernetes 开发者峰会上讨论这些主题以及更多内容。欢迎您参加我们的会议(用户、客户、软件和硬件供应商都欢迎),并为工作组做出贡献!