本文发表于一年多前。旧文章可能包含过时内容。请检查页面中的信息自发布以来是否已变得不正确。
Gardener - Kubernetes 植物学家
如今,Kubernetes 已成为在云中运行软件的自然选择。越来越多的开发人员和公司正在将其应用程序容器化,其中许多正在采用 Kubernetes 来自动化部署其云原生工作负载。
有许多开源工具可以帮助创建和更新单个 Kubernetes 集群。然而,您需要的集群越多,操作、监控、管理以及保持所有集群处于活动状态并保持最新状态就越困难。
这正是“Gardener”项目所关注的。它不仅仅是另一个配置工具,而是旨在将 Kubernetes 集群作为服务进行管理。它在各种云提供商上提供符合 Kubernetes 标准的集群,并能够大规模维护数百或数千个集群。在 SAP,我们不仅在自己的平台中面临这种异构多云和本地挑战,而且在所有实施 Kubernetes 和云原生的或大或小的客户那里也遇到了同样的需求。
受 Kubernetes 可能性和自托管能力的启发,Gardener 的基础是 Kubernetes 本身。虽然自托管(即在 Kubernetes 内部运行 Kubernetes 组件)在社区中是一个热门话题,但我们应用了一种特殊的模式,以最小的总拥有成本来操作大量集群。我们使用一个初始的 Kubernetes 集群(称为“种子”集群),并将最终用户集群的控制平面组件(如 API 服务器、调度器、控制器管理器、etcd 等)作为简单的 Kubernetes pod 播种。本质上,种子集群的重点是提供大规模的强大控制平面即服务。根据我们的植物学术语,准备发芽的最终用户集群被称为“芽”集群。考虑到网络延迟和其他故障场景,我们建议每个云提供商和区域使用一个种子集群来托管许多芽集群的控制平面。
总的来说,这种重用 Kubernetes 原语的概念已经简化了控制平面的部署、管理、扩展和修补/更新。由于它建立在高度可用的初始种子集群之上,我们可以避免芽集群控制平面所需的多个仲裁主节点,从而减少浪费/成本。此外,实际的芽集群仅由工作节点组成,可以授予其所有者完全管理访问权限,从而构建必要的职责分离以提供更高级别的 SLO。因此,架构角色和操作所有权定义如下(参见`图 1`):
- Kubernetes 即服务提供商拥有、运营和管理花园集群和种子集群。它们代表所需景观/基础设施的一部分。
- 芽集群的控制平面在种子集群中运行,因此在服务提供商的独立安全域内运行。
- 芽集群的机器在客户的云提供商账户和环境中运行,由客户拥有,但仍由 Gardener 管理。
- 对于本地或私有云场景,种子集群(和 IaaS)的所有权和管理委托是可行的。

图 1 包含组件的 Gardener 技术景观。
Gardener 作为聚合 API 服务器开发,并带有一组捆绑的控制器。它在另一个专用的 Kubernetes 集群(称为“花园”集群)中运行,并通过自定义资源扩展 Kubernetes API。最重要的是,Shoot 资源允许以声明方式描述用户 Kubernetes 集群的整个配置。相应的控制器将像原生的 Kubernetes 控制器一样,监视这些资源并将世界的实际状态带到所需状态(导致创建、协调、更新、升级或删除操作)。以下示例清单显示了需要指定的内容:
apiVersion: garden.sapcloud.io/v1beta1
kind: Shoot
metadata:
name: dev-eu1
namespace: team-a
spec:
cloud:
profile: aws
region: us-east-1
secretBindingRef:
name: team-a-aws-account-credentials
aws:
machineImage:
ami: ami-34237c4d
name: CoreOS
networks:
vpc:
cidr: 10.250.0.0/16
...
workers:
- name: cpu-pool
machineType: m4.xlarge
volumeType: gp2
volumeSize: 20Gi
autoScalerMin: 2
autoScalerMax: 5
dns:
provider: aws-route53
domain: dev-eu1.team-a.example.com
kubernetes:
version: 1.10.2
backup:
...
maintenance:
...
addons:
cluster-autoscaler:
enabled: true
...
一旦发送到花园集群,Gardener 将接收它并配置实际的芽集群。上面未显示的是,每个操作都会丰富 `Shoot` 的 `status` 字段,指示当前是否有操作正在运行并记录上次错误(如果有)以及相关组件的运行状况。用户能够以真正的 Kubernetes 风格配置和监控其集群的状态。我们的用户甚至编写了他们自己的自定义控制器来监视和修改这些 `Shoot` 资源。
技术深度探讨
Gardener 实现了 Kubernetes 启动方法;因此,它利用 Kubernetes 的能力来执行其操作。它提供了几个控制器(参见 `[A]`)来监视 `Shoot` 资源,其中主控制器负责创建、更新和删除等标准操作。另一个名为“芽护理”的控制器执行定期健康检查和垃圾回收,而第三个控制器(“芽维护”)的任务是涵盖诸如将芽的机器映像更新到最新可用版本等操作。
对于每个芽,Gardener 在种子集群中创建一个专用的 `Namespace`,并带有适当的安全策略,并在其中预先创建稍后作为 `Secrets` 管理的所需证书。
etcd
Kubernetes 集群的后端数据存储 etcd(参见 `[B]`)部署为具有一个副本和 `PersistentVolume(Claim)` 的 `StatefulSet`。我们遵循最佳实践,运行另一个 etcd 分片实例来存储芽的 `Events`。无论如何,主 etcd Pod 都通过一个侧车进行了增强,该侧车验证静态数据并定期拍摄快照,然后高效地备份到对象存储。如果 etcd 的数据丢失或损坏,侧车会从最新可用快照中恢复数据。我们计划开发增量/连续备份,以避免恢复时(在恢复情况下)已恢复的 etcd 状态与实际状态之间出现差异 [1]。
Kubernetes 控制平面
如上所述,我们将其他 Kubernetes 控制平面组件放入原生 `Deployments` 中,并使用滚动更新策略运行它们。通过这样做,我们不仅可以利用 Kubernetes 现有的部署和更新能力,还可以利用其监控和活跃度能力。虽然控制平面本身使用集群内通信,但 API 服务器的 `Service` 通过负载均衡器暴露以进行外部通信(参见 `[C]`)。为了统一生成部署清单(主要取决于 Kubernetes 版本和云提供商),我们决定使用 Helm chart,而 Gardener 只利用 Tiller 的渲染能力,但直接部署生成的清单,根本不运行 Tiller [2]。
基础设施准备
创建集群的首要要求之一是在云提供商端准备完善的基础设施,包括网络和安全组。在我们当前的 Gardener 提供商特定树内实现(称为“植物学家”)中,我们使用 Terraform 来完成此任务。Terraform 为主要的云提供商提供了很好的抽象,并实现了并行性、重试机制、依赖图、幂等性等功能。然而,我们发现 Terraform 在错误处理方面具有挑战性,并且它不提供技术接口来提取错误的根本原因。目前,Gardener 根据芽规范生成 Terraform 脚本,并将其存储在种子集群相应命名空间中的 `ConfigMap` 中。Terraformer 组件然后作为 `Job` 运行(参见 `[D]`),执行挂载的 Terraform 配置,并将生成的स्टेट写回到另一个 `ConfigMap` 中。以这种方式使用 Job 原语有助于继承其重试逻辑,并实现对临时连接问题或资源限制的容错。此外,Gardener 只需访问种子集群的 Kubernetes API 即可为底层 IaaS 提交 Job。这种设计对于通常不公开 IaaS API 的私有云场景非常重要。
机器控制器管理器
接下来需要的是用于调度集群实际工作负载的节点。然而,Kubernetes 不提供请求节点的原语,这迫使集群管理员使用外部机制。考虑因素包括完整的生命周期,从初始供应开始,到提供安全修复、执行健康检查和滚动更新。虽然我们最初使用实例化静态机器或利用云提供商的实例模板来创建工作节点,但我们得出结论(也基于我们之前运行云平台的生产经验),这种方法需要大量的努力。在 KubeCon 2017 的讨论中,我们认识到管理集群节点的最佳方法当然是再次应用核心 Kubernetes 概念,并教导系统自我管理它运行的节点/机器。为此,我们开发了 机器控制器管理器(参见 `[E]`),它通过 `MachineDeployment`、`MachineClass`、`MachineSet` 和 `Machine` 资源扩展了 Kubernetes,并支持在 Kubernetes 上下文中声明式管理(虚拟)机器,就像 `Deployments`、`ReplicaSets` 和 `Pods` 一样。我们重用了现有 Kubernetes 控制器的代码,只需抽象一些 IaaS/云提供商特定的方法,用于在专用驱动程序中创建、删除和列出机器。比较 Pod 和机器时,一个微妙的区别变得显而易见:创建虚拟机直接导致成本,如果发生意外情况,这些成本会迅速增加。为了防止这种失控,机器控制器管理器带有一个安全控制器,可以终止孤立的机器,并冻结超出特定阈值和超时的 `MachineDeployment` 和 `MachineSet` 的推出。此外,我们利用现有的官方 集群自动伸缩器,它已经包含了确定哪个节点池应该扩容或缩容的复杂逻辑。由于其云提供商接口设计良好,我们使自动伸缩器能够在触发扩容或缩容时直接修改相应 `MachineDeployment` 资源中的副本数量。
附加组件
除了提供正确设置的控制平面外,每个 Kubernetes 集群都需要一些系统组件才能工作。通常,这些是 kube-proxy、叠加网络、集群 DNS 和入口控制器。除此之外,Gardener 允许订购用户可在芽资源定义中配置的可选附加组件,例如 Heapster、Kubernetes Dashboard 或 Cert-Manager。同样,Gardener 通过 Helm chart 渲染所有这些组件的清单(部分改编并精选自 上游 charts 仓库)。但是,这些资源在芽集群中进行管理,因此具有完全管理访问权限的用户可以对其进行调整。因此,Gardener 通过利用现有的看门狗 kube-addon-manager(参见 `[F]`)来确保这些部署的资源始终与计算/期望的配置匹配。
网络隔离
虽然芽集群的控制平面运行在由友好的平台提供商管理和提供的种子集群中,但工作节点通常部署在用户独立的云提供商(计费)账户中。通常,这些工作节点放置在私有网络中 [3],种子控制平面中的 API 服务器使用基于 ssh 的简单 VPN 解决方案(参见 `[G]`)与这些网络建立直接通信。我们最近已将基于 SSH 的实现迁移到基于 OpenVPN 的实现,这显著增加了网络带宽。
监控与日志
监控、警报和日志对于监督集群并保持其健康至关重要,以避免中断和其他问题。Prometheus 已成为 Kubernetes 领域最常用的监控系统。因此,我们在每个种子的 `garden` 命名空间中部署一个中央 Prometheus 实例。它从所有种子的 kubelet 收集指标,包括在种子集群中运行的所有 pod 的指标。此外,在每个控制平面旁边,都会为芽本身提供一个专用的租户 Prometheus 实例(参见 `[H]`)。它收集其自身控制平面以及在芽的工作节点上运行的 pod 的指标。前者是通过从中央 Prometheus 的联邦端点获取数据并过滤特定芽的相关控制平面 pod 来完成的。除此之外,Gardener 部署了两个 kube-state-metrics 实例,一个负责控制平面,一个负责工作负载,暴露集群级指标以丰富数据。节点导出器提供更详细的节点统计信息。专用的租户 Grafana 仪表板通过清晰的仪表板显示分析和见解。我们还为关键事件定义了警报规则,并使用 AlertManager 在触发任何警报时向操作员和支持团队发送电子邮件。
[1] 这也是不支持时间点恢复的原因。到目前为止,Kubernetes 中尚未实现可靠的基础设施协调。因此,在不刷新相关集群的实际工作负载和状态的情况下从旧备份恢复通常没有多大帮助。
[2] 这个决定最相关的标准是 Tiller 需要一个端口转发连接进行通信,我们发现这对于我们的自动化用例来说过于不稳定和容易出错。尽管如此,我们期待 Helm v3 能够通过 `CustomResourceDefinitions` 与 Tiller 交互。
[3] Gardener 提供使用 Terraformer 创建和准备这些网络,或者可以指示它重用现有网络。
可用性和交互
尽管管理 Gardener 只需使用熟悉的 `kubectl` 命令行工具,但我们提供了一个中央仪表板以方便交互。它使用户可以轻松跟踪其集群的健康状况,并使操作员能够监控、调试和分析他们负责的集群。芽集群被分组到逻辑项目中,团队可以在其中协作管理一组集群,甚至可以通过集成的票务系统(例如 GitHub Issues)跟踪问题。此外,仪表板还帮助用户添加和管理其基础设施账户的 Secret,并在一个地方查看所有芽集群最相关的数据,同时独立于它们部署到的云提供商。
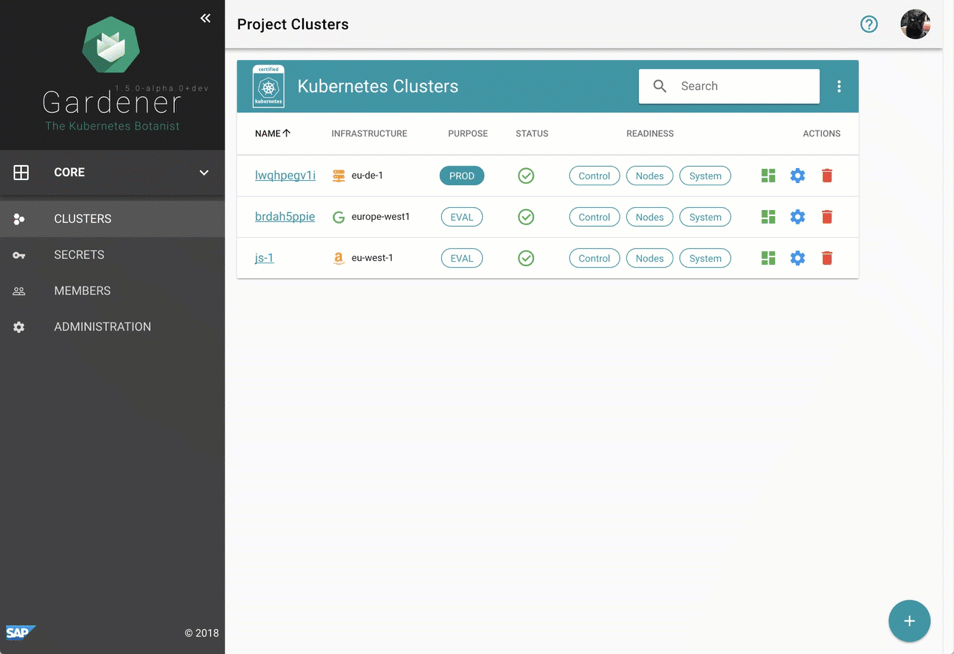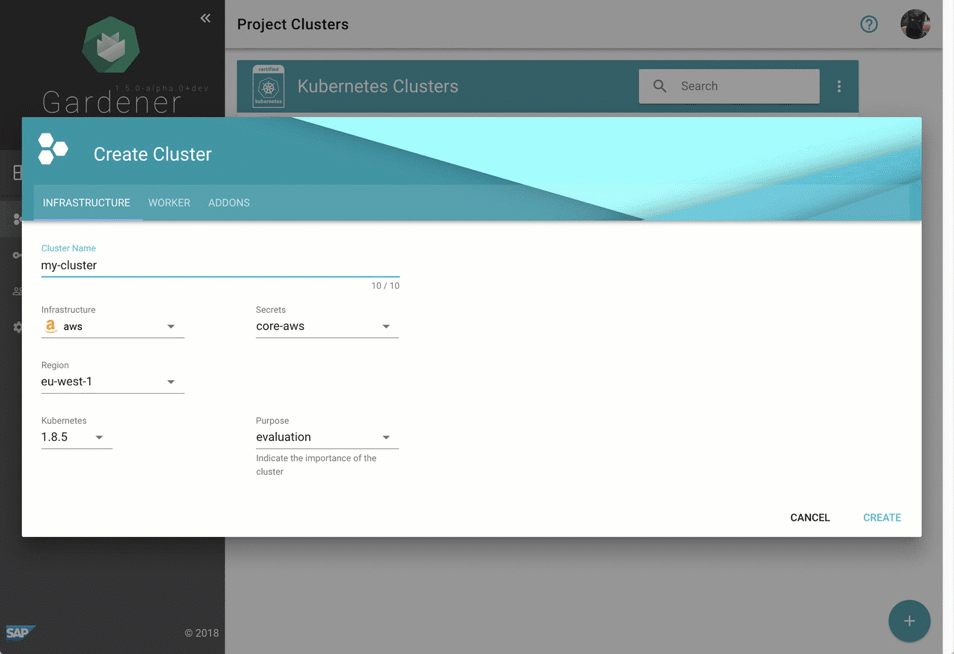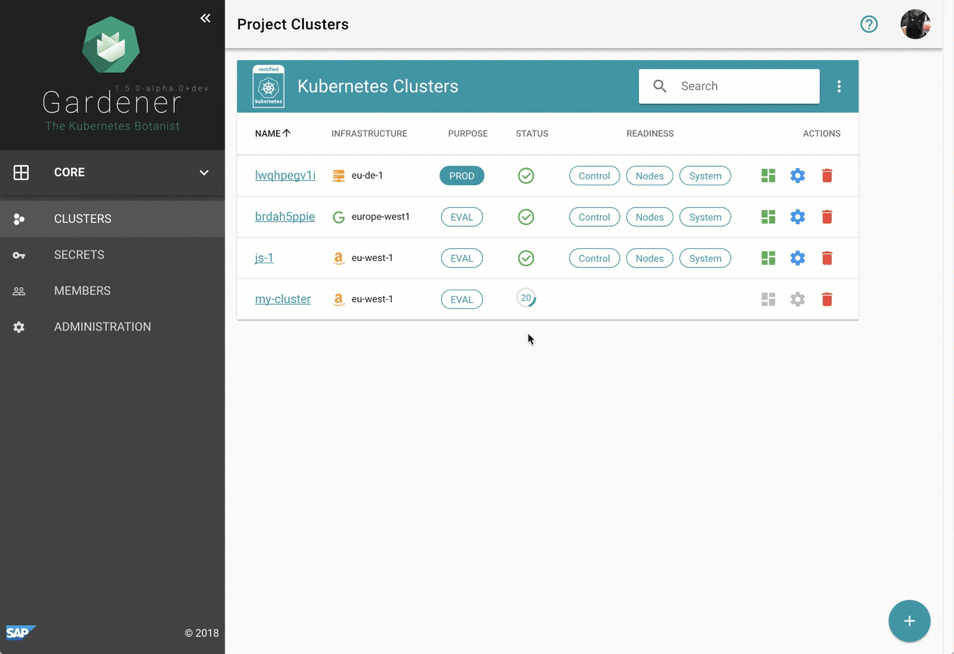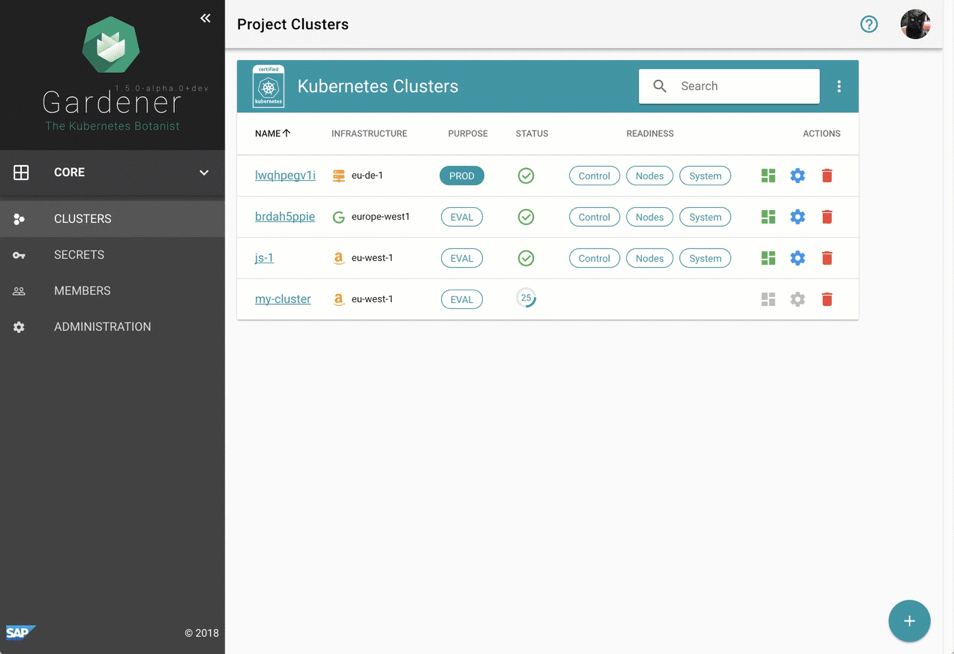
图 2 动画 Gardener 仪表板。
更侧重于开发人员和操作员的职责,Gardener 命令行客户端 `gardenctl` 通过引入简单的、高级别的抽象和简单的命令来简化管理任务,这些命令有助于从大量种子集群和芽集群中整合和多路复用信息和操作。
$ gardenctl ls shoots
projects:
- project: team-a
shoots:
- dev-eu1
- prod-eu1
$ gardenctl target shoot prod-eu1
[prod-eu1]
$ gardenctl show prometheus
NAME READY STATUS RESTARTS AGE IP NODE
prometheus-0 3/3 Running 0 106d 10.241.241.42 ip-10-240-7-72.eu-central-1.compute.internal
URL: https://user:password@p.prod-eu1.team-a.seed.aws-eu1.example.com
展望与未来计划
Gardener 已经能够管理 AWS、Azure、GCP、OpenStack 上的 Kubernetes 集群 [4]。实际上,由于它只依赖于 Kubernetes 原语,因此它很好地满足了私有云或本地要求。从 Gardener 的角度来看,唯一的区别是底层基础设施的质量和可扩展性——Kubernetes 的通用语言确保了我们方法的强大可移植性保证。
然而,挑战依然存在。我们正在探讨在此开源项目中包含一个选项的可能性,以创建联合控制平面,委托给多个芽集群。在前面的部分中,我们没有解释如何引导花园集群和种子集群本身。您确实可以使用任何生产就绪的集群配置工具或云提供商的 Kubernetes 即服务产品。我们已经构建了一个基于 Terraform 的统一工具 Kubify,并重用了许多提及的 Gardener 组件。我们设想所需的 Kubernetes 基础设施能够通过初始引导 Gardener 完全生成,并且我们已经在讨论如何实现这一点。
我们关注的另一个重要话题是灾难恢复。当种子集群发生故障时,用户的静态工作负载将继续运行。然而,管理集群将不再可能。我们正在考虑将受灾芽集群的控制平面迁移到另一个种子集群。从概念上讲,这种方法是可行的,我们已经具备了实施所需组件,例如自动化 etcd 备份和恢复。这个项目的贡献者不仅有为生产开发 Gardener 的任务,我们大多数人甚至以真正的 DevOps 模式运行它。我们完全信任 Kubernetes 的概念,并致力于遵循“自食其力”的方法。
为了实现 Botanists(其中包含基础设施提供商特定的实现部分)更独立的演进,我们计划描述定义良好的接口,并将 Botanists 分解为自己的组件。这类似于 Kubernetes 目前正在对 cloud-controller-manager 所做的事情。目前,所有云特定功能都是核心 Gardener 存储库的一部分,这为扩展或支持新的云提供商设置了软障碍。
当我们看看芽集群是如何实际配置的,我们需要获得更多关于拥有数千个节点和 Pod(或更多)的真正大型集群如何表现的经验。我们可能需要为大型集群部署(例如)API 服务器和其他组件,以实现横向扩展以分散负载。幸运的是,基于 Prometheus 的自定义指标的水平 Pod 自动伸缩将使我们的设置相对容易实现。此外,在我们的集群上运行生产工作负载的团队反馈说,Gardener 应该支持预先安排好的 Kubernetes QoS。毋庸置疑,我们的愿望是集成并贡献到 Kubernetes Autopilot 的愿景。
[4] 原型已经验证了电信云和阿里云。
Gardener 是开源的
Gardener 项目作为开源项目开发,并托管在 GitHub 上:https://github.com/gardener
SAP 自 2017 年年中开始致力于 Gardener 项目,并专注于构建一个易于演进和扩展的项目。因此,我们现在正在寻找更多的合作伙伴和贡献者加入该项目。如上所述,我们完全依赖 Kubernetes 原语、附加组件和规范,并采纳其创新的云原生方法。我们期待与 Kubernetes 社区保持一致并为其做出贡献。事实上,我们设想将整个项目贡献给 CNCF。
目前,与社区合作的一个重要焦点是几个月前成立的 SIG Cluster Lifecycle 中的 Cluster API 工作组。其主要目标是定义一个表示 Kubernetes 集群的可移植 API。这包括控制平面和底层基础设施的配置。我们将现有 Shoot 和 Machine 资源与社区正在开发的内容进行比较,重叠之处引人注目。因此,我们加入了这个工作组,并积极参与其定期会议,努力回馈我们从生产中获得的经验教训。自私地说,塑造一个健壮的 API 也符合我们的利益。
如果您看到 Gardener 项目的潜力,请在 GitHub 上了解更多信息,并通过提问、参与讨论和贡献代码来帮助我们改进 Gardener。另外,请尝试我们的快速入门设置。
我们期待在那里见到您!