本文发表于一年多前。旧文章可能包含过时内容。请检查页面中的信息自发布以来是否已变得不正确。
特性亮点:CPU Manager
这篇博客文章介绍了 CPU 管理器,这是 Kubernetes 中的一个 Beta 功能。CPU 管理器功能通过为某些 Pod 容器分配独占 CPU,改进了 Kubernetes 节点代理 Kubelet 中的工作负载放置。
听起来不错!但是 CPU 管理器对我有什么帮助呢?
这取决于您的工作负载。Kubernetes 集群中的单个计算节点可以运行许多 Pod,其中一些 Pod 可能运行 CPU 密集型工作负载。在这种情况下,Pod 可能会争夺该计算节点中可用的 CPU 资源。当这种争用加剧时,工作负载可能会移动到不同的 CPU,具体取决于 Pod 是否受到限制以及调度时 CPU 的可用性。还可能存在工作负载对上下文切换敏感的情况。在所有上述场景中,工作负载的性能都可能受到影响。
如果您的工作负载对此类场景敏感,则可以启用 CPU 管理器,通过为您的工作负载分配独占 CPU 来提供更好的性能隔离。
CPU 管理器可能有助于具有以下特征的工作负载:
- 对 CPU 限制效应敏感。
- 对上下文切换敏感。
- 对处理器缓存未命中敏感。
- 受益于共享处理器资源(例如,数据和指令缓存)。
- 对跨套接字内存流量敏感。
- 对同一物理 CPU 核心的超线程敏感或需要它们。
好的!我该如何使用它?
使用 CPU 管理器很简单。首先,在集群计算节点上运行的 Kubelet 中启用静态策略的 CPU 管理器。然后将您的 Pod 配置为 Guaranteed (QoS) 服务质量类别。为需要独占核心的容器请求整数个 CPU 核心(例如,1000m,4000m)。像以前一样创建您的 Pod(例如,kubectl create -f pod.yaml)。然后,CPU 管理器将根据其 CPU 请求为 Pod 中的每个容器分配独占 CPU。
apiVersion: v1
kind: Pod
metadata:
name: exclusive-2
spec:
containers:
- image: quay.io/connordoyle/cpuset-visualizer
name: exclusive-2
resources:
# Pod is in the Guaranteed QoS class because requests == limits
requests:
# CPU request is an integer
cpu: 2
memory: "256M"
limits:
cpu: 2
memory: "256M"
请求两个独占 CPU 的 Pod 规范。
嗯……CPU 管理器是如何工作的?
对于 Kubernetes,以及本博客文章的目的,我们将讨论大多数 Linux 发行版中可用的三种 CPU 资源控制。前两种是 CFS 份额(此系统上我的加权公平 CPU 时间份额是多少)和 CFS 配额(在一段时间内我的 CPU 时间硬上限是多少)。CPU 管理器使用第三种控制,称为 CPU 亲和性(我被允许在哪些逻辑 CPU 上执行)。
默认情况下,在 Kubernetes 集群的计算节点上运行的所有 Pod 和容器都可以在系统中任何可用的核心上执行。可分配的份额和配额总量受到显式为 Kubernetes 和系统守护进程保留的 CPU 资源的限制。但是,可以使用 Pod 规范中的 CPU 限制来指定正在使用的 CPU 时间的限制。Kubernetes 使用 CFS 配额来强制执行 Pod 容器的 CPU 限制。
当启用“静态”策略的 CPU 管理器时,它管理一个共享的 CPU 池。最初,这个共享池包含计算节点中的所有 CPU。当 Kubelet 创建一个具有整数 CPU 请求的 Guaranteed Pod 中的容器时,该容器的 CPU 将从共享池中移除,并专门分配给该容器的整个生命周期。其他容器将从这些独占分配的 CPU 上迁移出去。
所有非独占 CPU 容器(Burstable、BestEffort 和具有非整数 CPU 的 Guaranteed)都在共享池中剩余的 CPU 上运行。当具有独占 CPU 的容器终止时,其 CPU 将重新添加到共享 CPU 池中。
请提供更多详细信息……
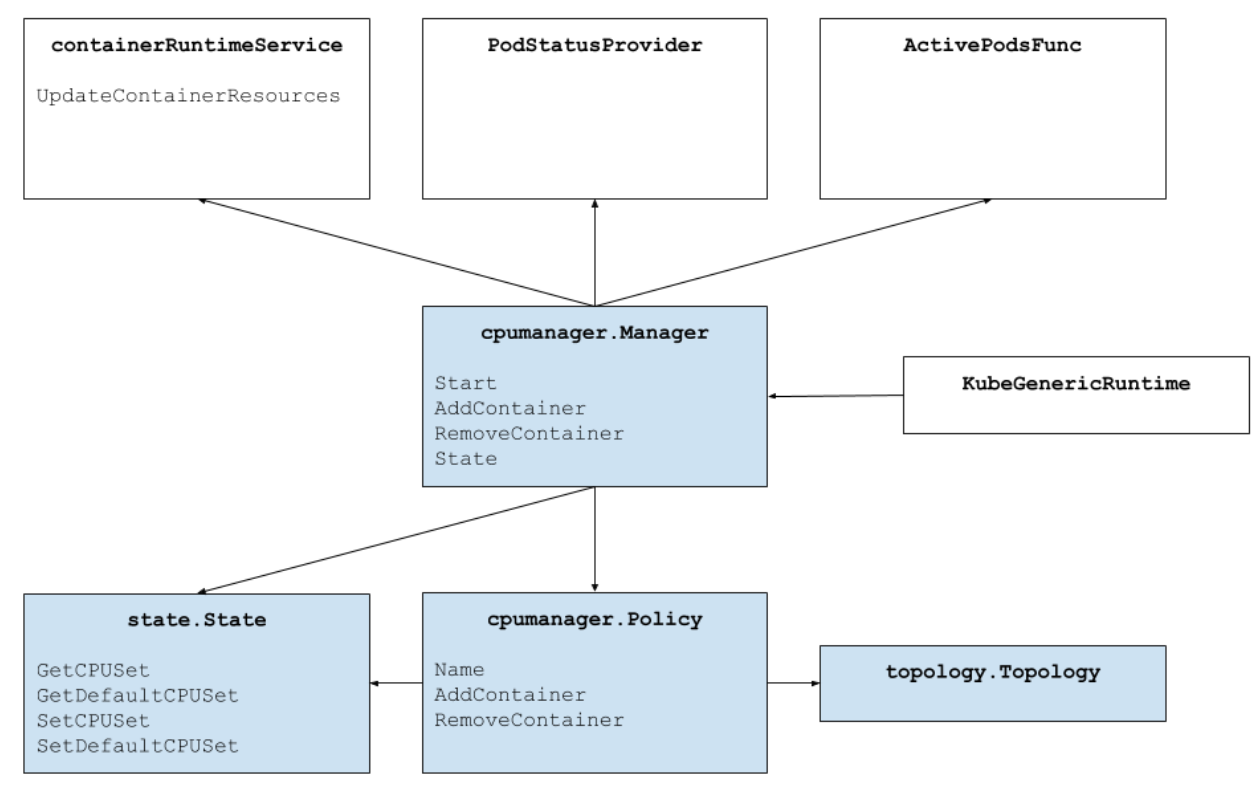
上图显示了 CPU 管理器的架构。CPU 管理器使用容器运行时接口的 UpdateContainerResources 方法来修改容器可以运行的 CPU。管理器定期将每个运行中容器的当前 CPU 资源状态与 cgroupfs 进行协调。
CPU 管理器使用 策略来决定 CPU 的分配。目前实现了两种策略:None 和 Static。默认情况下,从 Kubernetes 1.10 版本开始,CPU 管理器启用 None 策略。
静态策略将独占 CPU 分配给 Guaranteed QoS 类别中请求整数 CPU 的 Pod 容器。在尽力而为的基础上,静态策略会按照以下顺序拓扑分配 CPU:
- 如果可用且容器请求至少一个完整的处理器套接字 worth 的 CPU,则分配同一处理器套接字中的所有 CPU。
- 如果可用且容器请求一个完整的核心 worth 的 CPU,则分配同一物理 CPU 核心中的所有逻辑 CPU(超线程)。
- 分配任何可用的逻辑 CPU,优先从同一套接字获取 CPU。
CPU 管理器如何改善性能隔离?
启用 CPU 管理器静态策略后,工作负载的性能可能会更好,原因如下:
- 可以为工作负载容器分配独占 CPU,而不是其他容器。这些容器不共享 CPU 资源。因此,当涉及攻击者或共置工作负载时,我们期望由于隔离而获得更好的性能。
- 由于我们可以将 CPU 分区到工作负载之间,因此工作负载使用的资源之间的干扰会减少。这些资源可能还包括缓存层次结构和内存带宽,而不仅仅是 CPU。这有助于总体上提高工作负载的性能。
- CPU 管理器尽力而为地按拓扑顺序分配 CPU。如果一个完整的套接字空闲,CPU 管理器将把该空闲套接字中的 CPU 独占分配给工作负载。这通过避免任何跨套接字流量来提高工作负载的性能。
- Guaranteed QoS Pod 中的容器受 CFS 配额限制。突发性很强的工作负载可能会被调度,在周期结束前用尽其配额,并被限制。在此期间,这些 CPU 可能有也可能没有有意义的工作要做。由于 CPU 配额和静态策略分配的独占 CPU 数量之间的资源计算一致,这些容器不受 CFS 限制(配额等于配额周期内最大可能的 CPU 时间)。
好的!好的!您有任何结果吗?
很高兴您问了!为了了解在 Kubelet 中启用 CPU 管理器功能所带来的性能改进和隔离,我们在一台启用了超线程的双套接字计算节点(Intel Xeon CPU E5-2680 v3)上进行了实验。该节点包含 48 个逻辑 CPU(24 个物理核心,每个核心具有 2 路超线程)。在这里,我们使用基准测试和真实世界工作负载,在三种不同的场景下演示了 CPU 管理器功能提供的性能优势和隔离。
我该如何解读这些图表?
对于每种场景,我们都展示了箱线图,说明了启用和未启用 CPU 管理器时运行基准测试或真实世界工作负载的标准化执行时间及其变异性。运行的执行时间已标准化为性能最佳的运行(y 轴上的 1.00 代表性能最佳的运行,越低越好)。箱线图的高度显示了性能的变异性。例如,如果箱线图是一条线,则各次运行的性能没有变异性。在箱线图中,中间线是中位数,上线是 75% 分位数,下线是 25% 分位数。箱线图的高度(即 75% 分位数和 25% 分位数之间的差异)定义为四分位距 (IQR)。胡须显示该范围之外的数据,点显示异常值。异常值定义为任何低于或高于下四分位数或上四分位数 1.5 倍 IQR 的数据。每次实验都运行了十次。
免受攻击者工作负载的保护
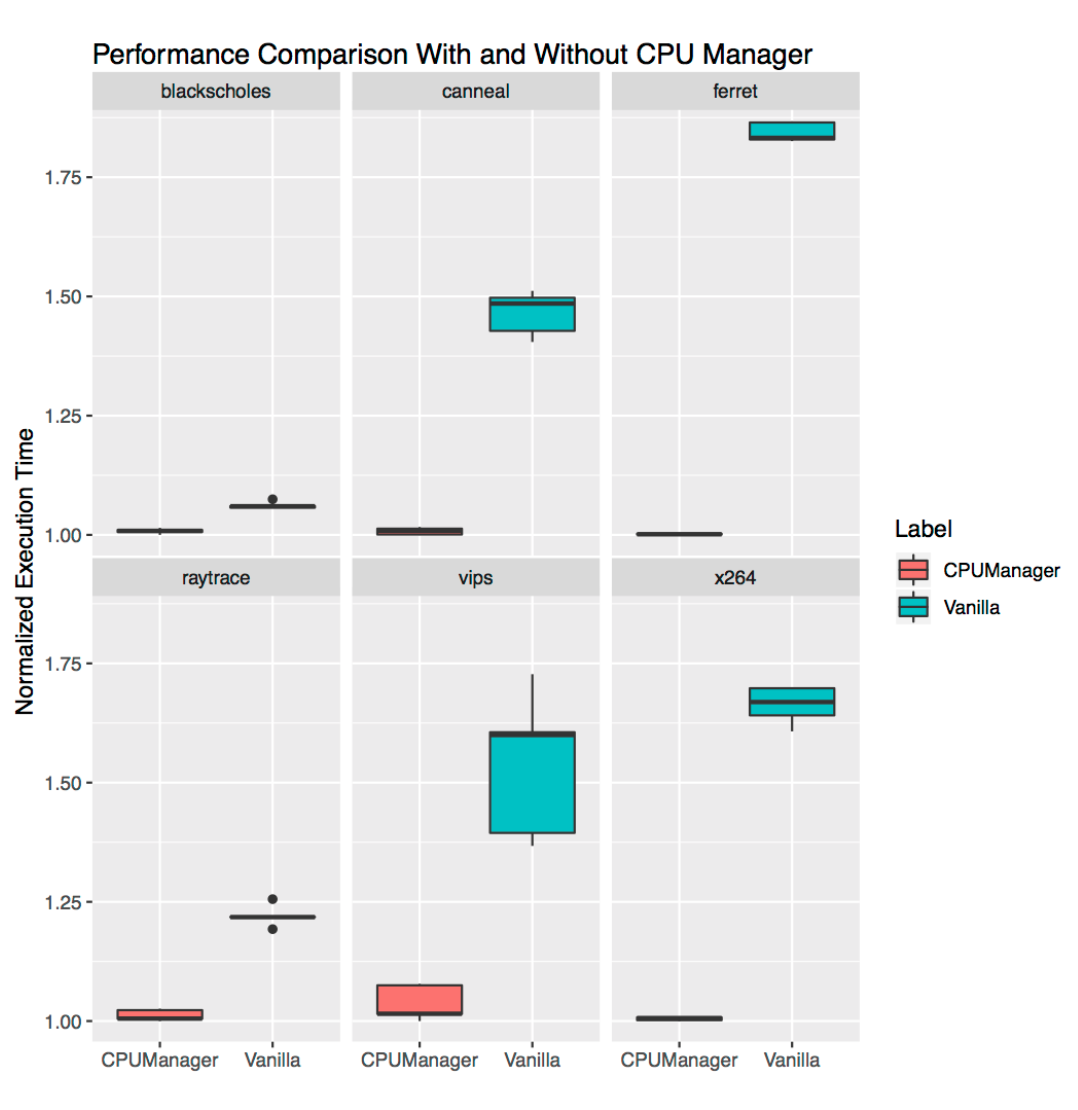
我们运行了来自 PARSEC 基准测试套件的六个基准测试(受害者工作负载),并与一个 CPU 压力容器(攻击者工作负载)共同定位,分别在启用和未启用 CPU 管理器功能的情况下进行。CPU 压力容器作为 Pod 运行在 Burstable QoS 类别中,请求 23 个 CPU,带有 --cpus 48 标志。基准测试作为 Pod 运行在 Guaranteed QoS 类别中,请求一个完整的套接字 CPU(此系统上为 24 个 CPU)。下图绘制了在启用和未启用 CPU 管理器静态策略的情况下,与压力 Pod 共同定位运行基准测试 Pod 的标准化执行时间。我们看到在所有测试用例中,启用静态策略后性能得到改善,性能变异性降低。
共置工作负载的性能隔离
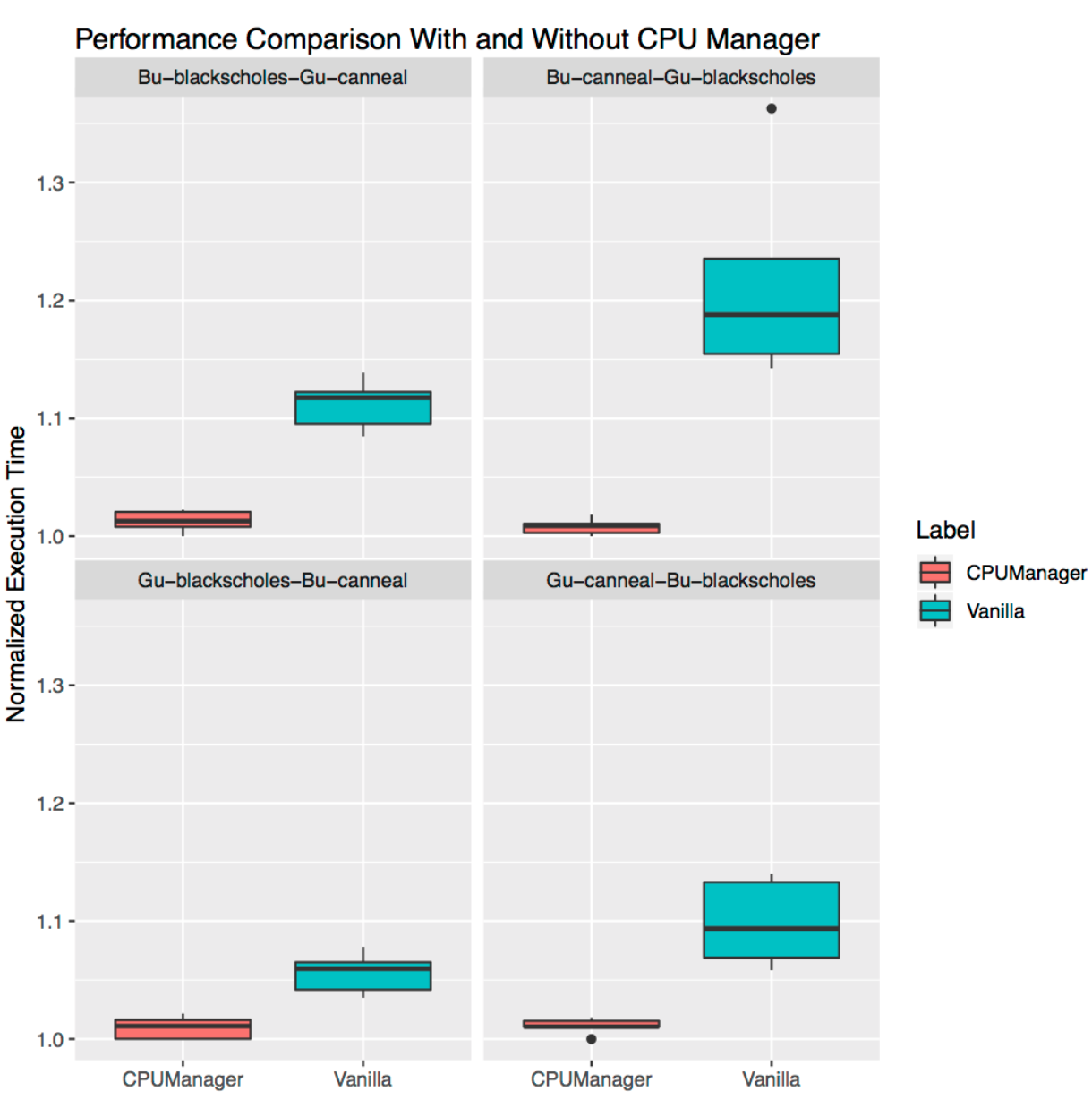
在本节中,我们演示了 CPU 管理器如何在共置工作负载场景中为多个工作负载带来益处。在下面的箱线图中,我们展示了 PARSEC 基准测试套件中的两个基准测试(Blackscholes 和 Canneal)在 Guaranteed (Gu) 和 Burstable (Bu) QoS 类别中相互共置运行的性能,分别在启用和未启用 CPU 管理器静态策略的情况下。
从左上角开始顺时针方向,我们分别显示了 Bu QoS 类别中的 Blackscholes 性能(左上)、Bu QoS 类别中的 Canneal 性能(右上)、Gu QoS 类别中的 Canneal 性能(右下)和 Gu QoS 类别中的 Blackscholes 性能(左下)。在每种情况下,它们都与 Gu QoS 类别中的 Canneal(左上)、Gu QoS 类别中的 Blackscholes(右上)、Bu QoS 类别中的 Blackscholes(右下)和 Bu QoS 类别中的 Canneal(左下)共同定位,按顺时针方向从左上角开始。例如,Bu-blackscholes-Gu-canneal 图(左上)显示了 Blackscholes 在 Bu QoS 类别中与 Gu QoS 类别中的 Canneal 共同运行时 Blackscholes 的性能。在每种情况下,Gu QoS 类别中的 Pod 请求一个完整套接字的核心(即 24 个 CPU),Bu QoS 类别中的 Pod 请求 23 个 CPU。
在所有测试中,两种共置工作负载的性能都更好,性能波动更小。例如,考虑 Bu-blackscholes-Gu-canneal(左上)和 Gu-canneal-Bu-blackscholes(右下)的情况。它们显示了在启用和未启用 CPU 管理器的情况下,Blackscholes 和 Canneal 同时运行的性能。在这个特殊情况下,由于 Canneal 属于 Gu QoS 类别并请求整数个 CPU 核心,它获得了 CPU 管理器提供的独占核心。但 Blackscholes 也获得了独占的 CPU 集,因为它是共享池中唯一的工作负载。因此,Blackscholes 和 Canneal 都从 CPU 管理器中获得了性能隔离的好处。
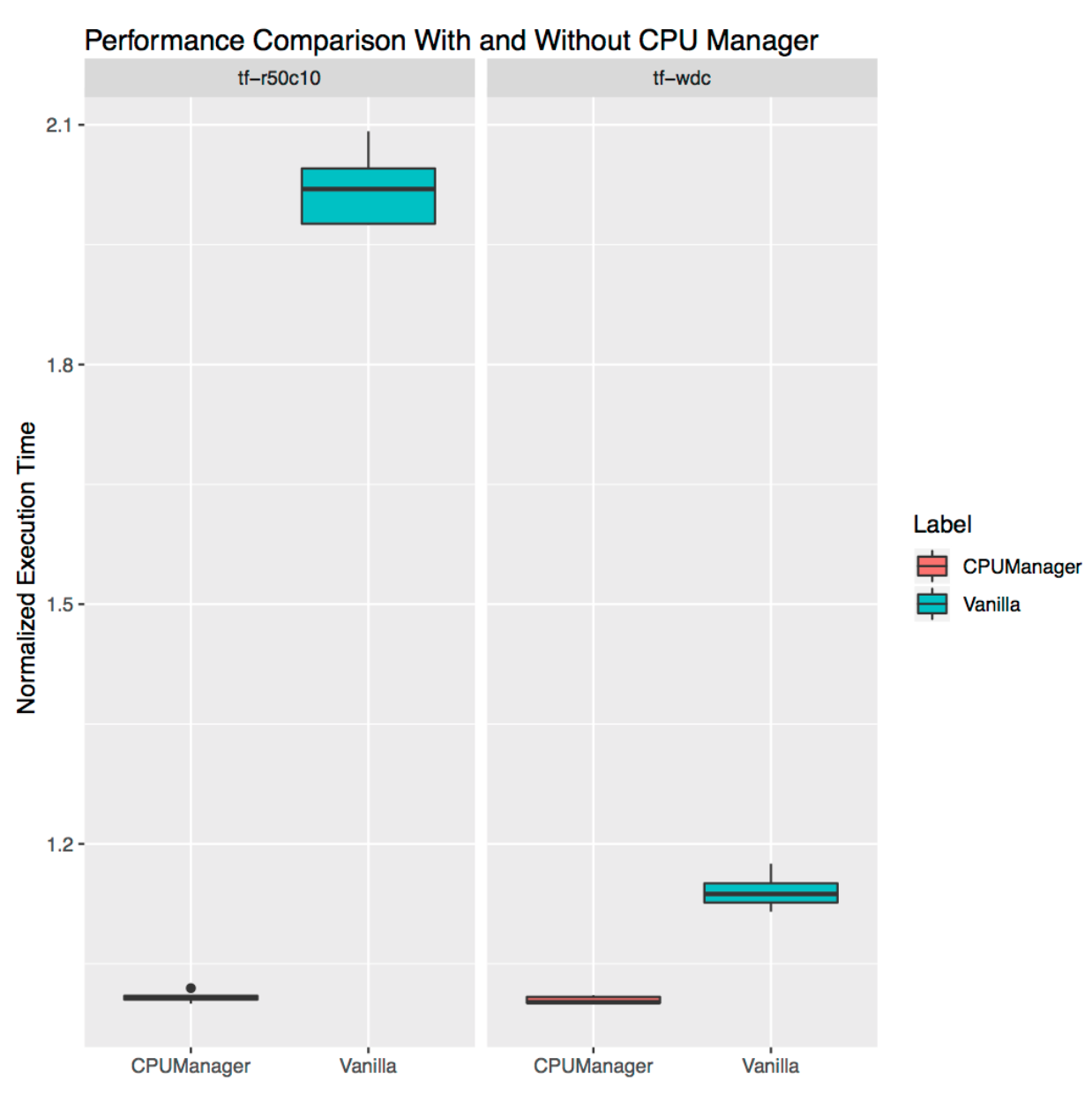
独立工作负载的性能隔离
本节展示了 CPU 管理器为独立真实世界工作负载提供的性能改进和隔离。我们使用了 TensorFlow 官方模型中的两个工作负载:wide and deep 和 ResNet。我们分别使用 census 和 CIFAR10 数据集用于 wide and deep 和 ResNet 模型。在每种情况下,Pod(wide and deep,ResNet)都请求 24 个 CPU,这相当于一个完整套接字的核心。如图所示,CPU 管理器在这两种情况下都实现了更好的性能隔离。
限制
用户可能希望在靠近连接外部设备(如加速器或高性能网卡)的总线套接字上分配 CPU,以避免跨套接字流量。CPU 管理器尚不支持这种对齐。由于 CPU 管理器尽力而为地分配属于一个套接字和物理核心的 CPU,因此它容易出现边缘情况并可能导致碎片化。CPU 管理器不考虑 isolcpus Linux 内核引导参数,尽管这据报道是某些低抖动用例的常见做法。
致谢
我们感谢社区成员为本功能做出的贡献或提供的反馈,包括 WG-Resource-Management 和 SIG-Node 的成员。cmx.io(感谢有趣的绘图工具)。
声明和免责声明
性能测试中使用的软件和工作负载可能已针对英特尔微处理器进行了性能优化。性能测试(如 SYSmark 和 MobileMark)是使用特定的计算机系统、组件、软件、操作和功能进行测量的。任何这些因素的更改都可能导致结果不同。您应该查阅其他信息和性能测试,以帮助您全面评估您的预期购买,包括该产品与其他产品组合时的性能。欲了解更多信息,请访问 www.intel.com/benchmarks。
英特尔技术的功能和优势取决于系统配置,可能需要启用硬件、软件或服务激活。性能因系统配置而异。任何计算机系统都无法绝对安全。请咨询您的系统制造商或零售商,或访问 intel.com 了解更多信息。
工作负载配置:https://gist.github.com/balajismaniam/fac7923f6ee44f1f36969c29354e3902 https://gist.github.com/balajismaniam/7c2d57b2f526a56bb79cf870c122a34c https://gist.github.com/balajismaniam/941db0d0ec14e2bc93b7dfe04d1f6c58 https://gist.github.com/balajismaniam/a1919010fe9081ca37a6e1e7b01f02e3 https://gist.github.com/balajismaniam/9953b54dd240ecf085b35ab1bc283f3c
系统配置:CPU 架构:x86_64 CPU 操作模式:32 位,64 位 字节序:小端序 CPU:48 在线 CPU 列表:0-47 每个核心线程数:2 每个套接字核心数:12 套接字数:2 NUMA 节点数:2 供应商 ID:GenuineIntel 型号名称:Intel(R) Xeon(R) CPU E5-2680 v3 内存 256 GB 操作系统/内核 Linux 3.10.0-693.21.1.el7.x86_64
Intel、Intel 标志、Xeon 是英特尔公司或其在美国和/或其他国家/地区的子公司的商标。
*其他名称和品牌可能被声称属于他人。© 英特尔公司。