本文发表于一年多前。旧文章可能包含过时内容。请检查页面中的信息自发布以来是否已变得不正确。
我激动人心的 Kubernetes 历史之旅
编者按:Sascha 是 SIG Release 的成员,正在研究许多其他与容器运行时相关的议题。欢迎通过 Twitter @saschagrunert 与他联系。
一个关于如何使用 Kubeflow、TensorFlow、Prow 和全自动 CI/CD 流水线,对 90,000 个 GitHub 问题和拉取请求进行数据科学研究的故事。
引言
在数据科学领域工作时,选择正确的步骤绝非易事。大多数数据科学家可能有他们自己的定制工作流,这些工作流的自动化程度可能因其工作领域而异。当尝试大规模自动化工作流时,使用 Kubernetes 可以极大地增强效果。在这篇博文中,我将带你踏上我的数据科学之旅,并将整个工作流集成到 Kubernetes 中。
我过去几个月进行的研究目标是,在 Kubernetes 仓库中找到关于数千个 GitHub 问题和拉取请求 (PR) 的任何有用信息。最终我得到的是一个完全自动化、在 Kubernetes 中运行的持续集成 (CI) 和部署 (CD) 数据科学工作流,由 Kubeflow 和 Prow 提供支持。你可能不熟悉它们,但我会详细解释它们的作用。我的工作源代码可以在 kubernetes-analysis GitHub 仓库中找到,其中包含所有与源代码相关的内容以及原始数据。但如何检索我所说的数据呢?嗯,故事从这里开始。
获取数据
我实验的基础是纯 JSON 格式的原始 GitHub API 数据。必要的数据可以通过 GitHub issues endpoint 检索,该端点以 REST API 形式返回所有拉取请求以及常规问题。在第一次迭代中,我导出了大约 91000 个问题和拉取请求,形成了一个巨大的 650 MiB 数据块。这花费了我大约 8 小时的数据检索时间,因为 GitHub API 确实有 速率限制。为了将这些数据放入 GitHub 仓库,我选择使用 xz(1) 进行压缩。结果是一个大约 25 MiB 大小的 tarball,非常适合仓库。
我必须找到一种定期更新数据集的方法,因为 Kubernetes 的问题和拉取请求会随着时间的推移被用户更新,也会创建新的。为了实现持续更新而无需一次又一次地等待 8 小时,我现在获取 上次更新 和当前时间之间的增量 GitHub API 数据。通过这种方式,持续集成作业可以定期更新数据,而我可以使用最新可用的数据集继续我的研究。
从工具的角度来看,我编写了一个一体化 Python 可执行文件,它允许我们通过专用子命令单独触发数据科学实验中的不同步骤。例如,要运行整个数据集的导出,我们可以调用
> export GITHUB_TOKEN=<MY-SECRET-TOKEN>
> ./main export
INFO | Getting GITHUB_TOKEN from environment variable
INFO | Dumping all issues
INFO | Pulling 90929 items
INFO | 1: Unit test coverage in Kubelet is lousy. (~30%)
INFO | 2: Better error messages if go isn't installed, or if gcloud is old.
INFO | 3: Need real cluster integration tests
INFO | 4: kubelet should know which containers it is managing
… [just wait 8 hours] …
要更新仓库中存储的最后一个时间戳之间的数据,我们可以运行
> ./main export --update-api
INFO | Getting GITHUB_TOKEN from environment variable
INFO | Retrieving issues and PRs
INFO | Updating API
INFO | Got update timestamp: 2020-05-09T10:57:40.854151
INFO | 90786: Automated cherry pick of #90749: fix: azure disk dangling attach issue
INFO | 90674: Switch core master base images from debian to distroless
INFO | 90086: Handling error returned by request.Request.ParseForm()
INFO | 90544: configurable weight on the CPU and memory
INFO | 87746: Support compiling Kubelet w/o docker/docker
INFO | Using already extracted data from data/data.pickle
INFO | Loading pickle dataset
INFO | Parsed 34380 issues and 55832 pull requests (90212 items)
INFO | Updating data
INFO | Updating issue 90786 (updated at 2020-05-09T10:59:43Z)
INFO | Updating issue 90674 (updated at 2020-05-09T10:58:27Z)
INFO | Updating issue 90086 (updated at 2020-05-09T10:58:26Z)
INFO | Updating issue 90544 (updated at 2020-05-09T10:57:51Z)
INFO | Updating issue 87746 (updated at 2020-05-09T11:01:51Z)
INFO | Saving data
这让我们对项目实际移动的速度有了一个概念:在一个周六中午(欧洲时间),5 个问题和拉取请求在字面上的 5 分钟内得到了更新!
有趣的是,Kubernetes 创始人之一 Joe Beda 创建了第一个 GitHub issue 提及单元测试覆盖率太低。该 issue 除了标题之外没有进一步的描述,也没有应用像我们从最近的 issues 和 pull request 中所了解的更高级的标签。但现在我们必须更深入地探索导出的数据,才能用它做些有用的事情。
探索数据
在开始创建和训练机器学习模型之前,我们必须了解数据的结构以及我们想要达到的总体目标。
为了更好地了解数据量,我们来看看 Kubernetes 仓库中随时间创建了多少问题和拉取请求
> ./main analyze --created
INFO | Using already extracted data from data/data.pickle
INFO | Loading pickle dataset
INFO | Parsed 34380 issues and 55832 pull requests (90212 items)
Python matplotlib 模块应该会弹出一个图表,看起来像这样

好吧,这看起来并不那么引人注目,但让我们对项目在过去 6 年中的增长有了一个印象。为了更好地了解项目开发的速度,我们可以查看“created-vs-closed”指标。这意味着在我们的时间轴上,如果一个问题或拉取请求被创建,我们会在 y 轴上加一;如果它被关闭,我们会减去一。现在图表看起来像这样
> ./main analyze --created-vs-closed

在2018年初,Kubernetes项目通过光荣的fejta-bot引入了一些更强大的生命周期管理。这会自动关闭长时间处于闲置状态的issues和拉取请求。这导致了大量issue被关闭,但拉取请求的关闭数量并不相同。例如,如果我们只查看拉取请求的created-vs-closed指标。
> ./main analyze --created-vs-closed --pull-requests

整体影响并不那么明显。我们可以看到,PR 图表中峰值数量的增加表明项目随时间推移正在加速发展。通常,K线图会是显示这种波动性相关信息的更好选择。我还想强调的是,项目的发展似乎在 2020 年初略有放缓。
在每次分析迭代中解析原始 JSON 并不是 Python 中最快的方法。这意味着我决定将更重要的信息,例如内容、标题和创建时间解析到专门的 问题 和 PR 类中。这些数据也将通过 pickle 序列化到仓库中,这使得启动速度更快,而无需依赖 JSON blob。
在我的分析中,一个拉取请求或多或少与一个问题相同,只是它包含一个发布说明。
Kubernetes 的发布说明写在 PR 的描述中,放在一个单独的 `release-note` 块中,像这样
```release-note
I changed something extremely important and you should note that.
```
这些发布说明在发布创建过程中会由 专门的发布工程工具,如 krel 进行解析,并会成为各种 CHANGELOG.md 文件和 发布说明网站 的一部分。这看起来像很多魔法,但最终,整个发布说明的质量会更高,因为它们易于编辑,并且 PR 评审者可以确保我们只记录真正的面向用户的更改,而没有其他内容。
在进行数据科学时,输入数据的质量是一个关键方面。我决定关注发布说明,因为与问题和 PR 中的普通描述相比,它们似乎具有最高的总体质量。除此之外,它们易于解析,我们不需要去除 各种问题 和 PR 模板 中的文本噪音。
标签,标签,标签
Kubernetes 中的问题和拉取请求在其生命周期中会应用不同的标签。它们通常通过单个斜杠(/)进行分组。例如,我们有 kind/bug 和 kind/api-change,或者 sig/node 和 sig/network。了解存在哪些标签组以及它们在仓库中的分布情况的一种简单方法是将其绘制成条形图
> ./main analyze --labels-by-group

看起来 sig/、kind/ 和 area/ 标签很常见。像 size/ 这样的标签目前可以忽略,因为这些标签是根据拉取请求的代码更改量自动应用的。我们说过我们想将发布说明作为输入数据,这意味着我们必须查看 PR 的标签分布。这意味着拉取请求上的前 25 个标签是
> ./main analyze --labels-by-name --pull-requests

同样,我们可以忽略诸如 lgtm(看起来不错)之类的标签,因为每个现在应该合并的 PR 都必须看起来不错。包含发布说明的拉取请求会自动应用 release-note 标签,这使得进一步筛选更加容易。这并不意味着每个包含该标签的 PR 都包含发布说明块。该标签可能是手动应用的,并且发布说明块的解析自项目开始以来并不存在。这意味着我们一方面可能会丢失相当数量的输入数据。另一方面,我们可以专注于尽可能高的数据质量,因为正确应用标签需要项目及其贡献者更高的成熟度。
从标签组的角度来看,我选择专注于 kind/ 标签。这些标签是 PR 作者必须手动应用的,它们在大量拉取请求中可用,并且也与面向用户的更改相关。此外,每个拉取请求都必须选择 kind/,因为它是 PR 模板的一部分。
好的,只关注包含发布说明的拉取请求时,这些标签的分布是怎样的呢?
> ./main analyze --release-notes-stats

有趣的是,我们大约有 7,000 个包含发布说明的拉取请求,但只有大约 5,000 个应用了 kind/ 标签。标签的分布不均,其中三分之一被标记为 kind/bug。这把我带到了数据科学之旅的下一个决定:我将构建一个二元分类器,为简单起见,它只能区分 bug(通过 kind/bug)和非 bug(未应用该标签)。
现在主要目标是能够根据我们已经拥有的社区历史数据,对新传入的发布说明进行分类,判断它们是否与 bug 相关。
在此之前,我建议您也玩一下 ./main analyze -h 子命令,以探索最新的数据集。您还可以查看我在分析仓库中提供的所有持续更新的资产。例如,这些是 Kubernetes 仓库中排名前 25 的 PR 创建者

构建机器学习模型
现在我们对数据集有了一个概念,可以开始构建第一个机器学习模型了。在实际构建模型之前,我们必须预处理从 PR 中提取的所有发布说明。否则,模型将无法理解我们的输入。
进行一些初步的自然语言处理 (NLP)
首先,我们必须定义要训练的词汇表。我决定选择 Python scikit-learn 机器学习库中的 TfidfVectorizer。这个向量化器能够接收我们的输入文本并从中创建一个庞大的词汇表。这就是我们所谓的词袋模型,其 n-gram 范围选择为 (1, 2)(一元词和二元词)。实际上,这意味着我们总是将第一个词和下一个词作为一个单一的词汇表条目(二元词)。我们也将单个词作为词汇表条目(一元词)。TfidfVectorizer 能够跳过多次出现的词(max_df),并要求最小数量(min_df)才能将词添加到词汇表中。我最初决定不更改这些值,仅仅是因为我直觉地认为发布说明是项目独有的东西。
像 min_df、max_df 和 n-gram 范围这样的参数可以看作是我们的一些超参数。这些参数必须在机器学习模型构建后的专门步骤中进行优化。这个步骤称为超参数调优,其基本含义是,我们用不同的参数进行多次训练,并比较模型的准确性。之后,我们选择准确性最佳的参数。
在训练过程中,向量化器将生成一个 data/features.json 文件,其中包含整个词汇表。这让我们很好地理解了这样一个词汇表可能是什么样子
[
…
"hostname",
"hostname address",
"hostname and",
"hostname as",
"hostname being",
"hostname bug",
…
]
这在整个词袋中产生了大约 50,000 个条目,数量相当庞大。先前对不同数据集的分析表明,根本无需考虑如此多的特征。一些通用数据集指出,20,000 个词汇表就足够了,更高的数量不再影响准确性。为此,我们可以使用 SelectKBest 特征选择器将词汇表缩小到只选择最重要的特征。然而,我仍然决定坚持使用前 50,000 个,以免对模型准确性产生负面影响。我们的数据量相对较少(大约 7,000 个样本),每个样本的词数也很少(大约 15 个),这已经让我怀疑我们是否有足够的数据。
向量化器不仅能够创建我们的词袋,而且还能够以 词频-逆文档频率 (tf-idf) 格式编码特征。这也是向量化器得名的原因,而这种编码的输出是机器学习模型可以直接使用的。向量化过程的所有细节都可以在源代码中找到。
创建多层感知器 (MLP) 模型
我决定选择一个简单的基于 MLP 的模型,该模型借助流行的 TensorFlow 框架构建。由于我们没有太多的输入数据,我们只使用两个隐藏层,因此模型基本上看起来像这样

创建模型时需要考虑许多其他超参数。这里我不会详细讨论它们,但它们对于优化模型中的类别数量(在我们的例子中只有两个)也很重要。
训练模型
在开始实际训练之前,我们必须将输入数据分成训练集和验证集。我选择使用大约 80% 的数据进行训练,20% 用于验证。我们还必须打乱输入数据,以确保模型不受排序问题的影响。训练过程的技术细节可以在 GitHub 源代码中找到。所以现在我们准备好最终开始训练了
> ./main train
INFO | Using already extracted data from data/data.pickle
INFO | Loading pickle dataset
INFO | Parsed 34380 issues and 55832 pull requests (90212 items)
INFO | Training for label 'kind/bug'
INFO | 6980 items selected
INFO | Using 5584 training and 1395 testing texts
INFO | Number of classes: 2
INFO | Vocabulary len: 51772
INFO | Wrote features to file data/features.json
INFO | Using units: 1
INFO | Using activation function: sigmoid
INFO | Created model with 2 layers and 64 units
INFO | Compiling model
INFO | Starting training
Train on 5584 samples, validate on 1395 samples
Epoch 1/1000
5584/5584 - 3s - loss: 0.6895 - acc: 0.6789 - val_loss: 0.6856 - val_acc: 0.6860
Epoch 2/1000
5584/5584 - 2s - loss: 0.6822 - acc: 0.6827 - val_loss: 0.6782 - val_acc: 0.6860
Epoch 3/1000
…
Epoch 68/1000
5584/5584 - 2s - loss: 0.2587 - acc: 0.9257 - val_loss: 0.4847 - val_acc: 0.7728
INFO | Confusion matrix:
[[920 32]
[291 152]]
INFO | Confusion matrix normalized:
[[0.966 0.034]
[0.657 0.343]]
INFO | Saving model to file data/model.h5
INFO | Validation accuracy: 0.7727598547935486, loss: 0.48470408514836355
混淆矩阵 的输出显示,我们的训练准确率相当高,但验证准确率可以更高一些。我们现在可以开始超参数调优,看看是否能进一步优化模型的输出。我将把这个实验留给您,并提示您使用 ./main train --tune 标志。
我们将模型 (data/model.h5)、向量化器 (data/vectorizer.pickle) 和特征选择器 (data/selector.pickle) 保存到磁盘,以便稍后用于预测目的,而无需额外的训练步骤。
首次预测
我们现在可以通过从磁盘加载模型并预测一些输入文本来测试模型
> ./main predict --test
INFO | Testing positive text:
Fix concurrent map access panic
Don't watch .mount cgroups to reduce number of inotify watches
Fix NVML initialization race condition
Fix brtfs disk metrics when using a subdirectory of a subvolume
INFO | Got prediction result: 0.9940581321716309
INFO | Matched expected positive prediction result
INFO | Testing negative text:
action required
1. Currently, if users were to explicitly specify CacheSize of 0 for
KMS provider, they would end-up with a provider that caches up to
1000 keys. This PR changes this behavior.
Post this PR, when users supply 0 for CacheSize this will result in
a validation error.
2. CacheSize type was changed from int32 to *int32. This allows
defaulting logic to differentiate between cases where users
explicitly supplied 0 vs. not supplied any value.
3. KMS Provider's endpoint (path to Unix socket) is now validated when
the EncryptionConfiguration files is loaded. This used to be handled
by the GRPCService.
INFO | Got prediction result: 0.1251964420080185
INFO | Matched expected negative prediction result
这两个测试都是实际存在的真实世界示例。我们也可以尝试一些完全不同的东西,比如我几分钟前发现的这条随机推文
./main predict "My dudes, if you can understand SYN-ACK, you can understand consent"
INFO | Got prediction result: 0.1251964420080185
ERROR | Result is lower than selected threshold 0.6
看起来它没有被归类为发布说明中的错误,这似乎是有效的。选择一个好的阈值也不容易,但坚持使用 > 50% 应该只是最低限度。
一切自动化
下一步是找到一种自动化方法,用新数据持续更新模型。如果我在我的仓库中更改任何源代码,那么我想获得关于模型测试结果的反馈,而无需在我自己的机器上运行训练。我希望利用 Kubernetes 集群中的 GPU 来更快地训练,并在 PR 合并后自动更新数据集。
借助 Kubeflow 流水线,我们可以满足大部分这些要求。我构建的流水线看起来像这样
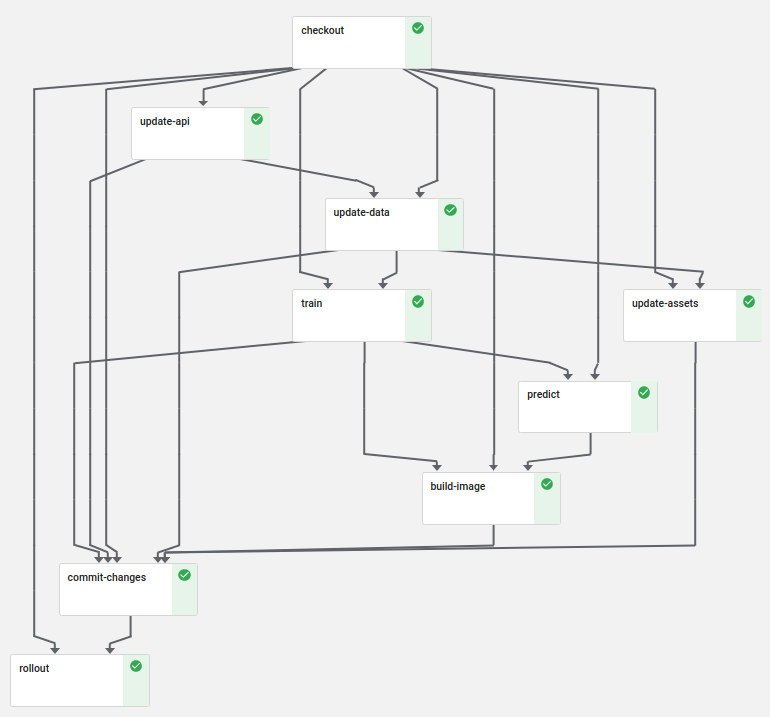
首先,我们签出 PR 的源代码,它将作为输出工件传递给所有其他步骤。然后,我们增量更新 API 和内部数据,之后我们在始终是最新的数据集上运行训练。预测测试在训练后验证我们没有因为更改而对模型产生不良影响。
我们还在管道中构建了一个容器镜像。这个容器镜像 将先前构建的模型、向量化器和选择器复制到容器中并运行 ./main serve。这样做时,我们启动一个 kfserving Web 服务器,该服务器可用于预测。您想自己尝试一下吗?只需像这样进行 JSON POST 请求,并针对端点运行预测
> curl https://kfserving.k8s.saschagrunert.de/v1/models/kubernetes-analysis:predict \
-d '{"text": "my test text"}'
{"result": 0.1251964420080185}
自定义 kfserving 实现非常直接,而部署则利用 Knative Serving 和 Istio ingress 网关在底层正确路由流量到集群并提供正确的服务集。
commit-changes 和 rollout 步骤仅在流水线运行在 master 分支上时才会执行。这些步骤确保我们在 master 分支和 kfserving 部署中始终拥有最新的数据集。 金丝雀发布步骤 首先创建一个新的金丝雀部署,它只接受 50% 的入站流量。在金丝雀成功部署后,它将被提升为服务的新主实例。这是一种很好的方式,可以确保部署按预期工作,并允许在金丝雀发布后进行额外的测试。
但是如何在创建拉取请求时触发 Kubeflow 流水线呢?Kubeflow 目前还没有这个功能。这就是我决定使用 Prow,即 Kubernetes 用于 CI/CD 的测试基础设施项目的原因。
首先,一个 24 小时周期性作业 确保我们仓库中至少每天都有最新的数据可用。然后,如果我们创建一个拉取请求,Prow 将运行整个 Kubeflow 流水线,而不提交或回滚任何更改。如果我们通过 Prow 合并拉取请求,另一个作业将在 master 分支上运行并更新数据以及部署。这不是很棒吗?
新 PR 的自动标记
预测 API 适用于测试,但现在我们需要一个真实的用例。Prow 支持可用于对任何 GitHub 事件采取行动的外部插件。我编写了一个插件,它使用 kfserving API 根据新的拉取请求进行预测。这意味着如果我们现在在 kubernetes-analysis 仓库中创建一个新的拉取请求,我们将看到以下内容
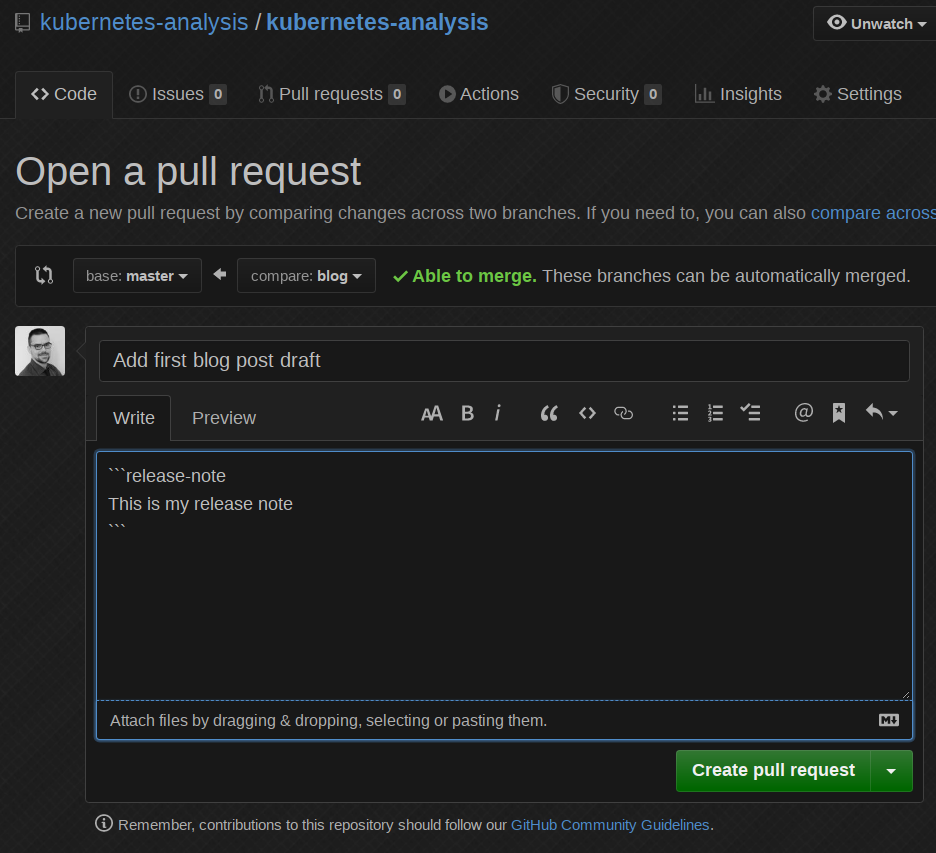
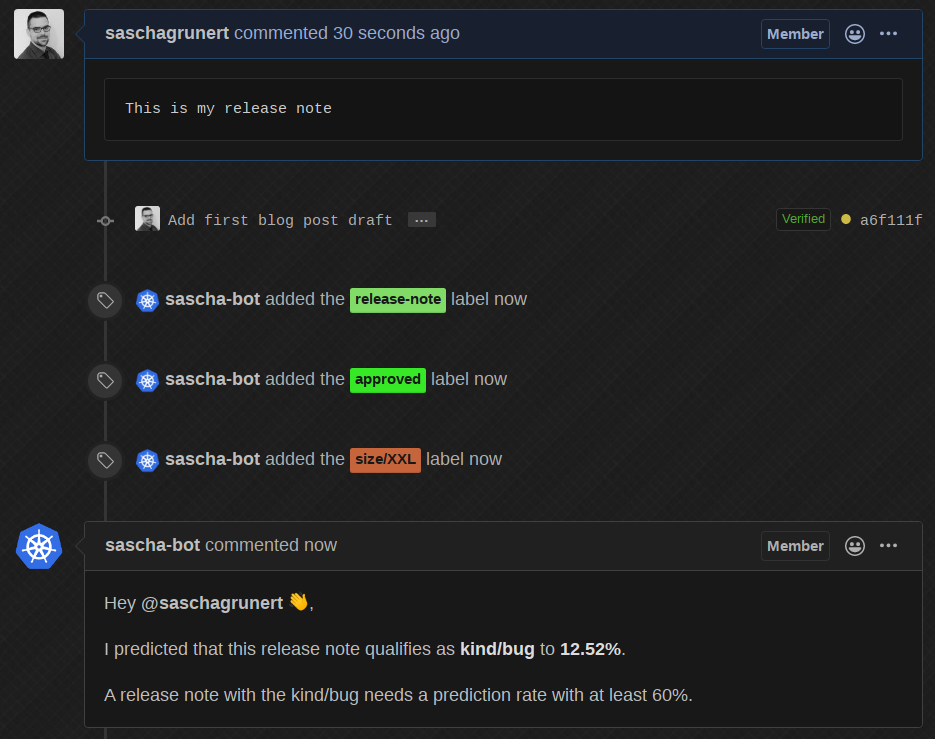
好吧,酷,现在让我们根据现有数据集中的一个真实 bug 来修改发布说明
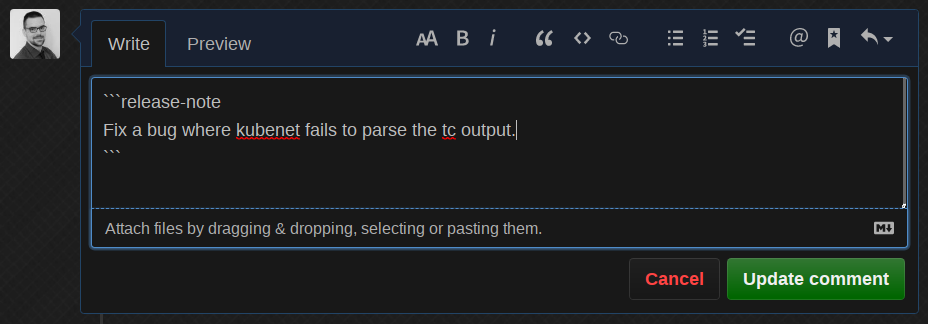

机器人编辑了自己的评论,以大约 90% 的概率将其预测为 kind/bug 并自动添加了正确的标签!现在,如果我们将它改回一些不同的——显然是错误的——发布说明
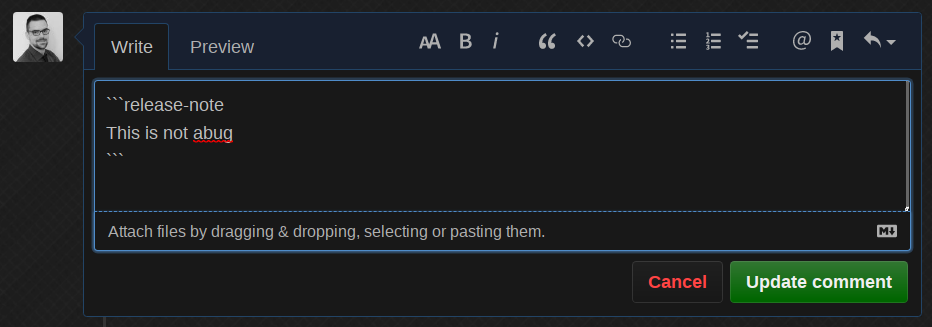
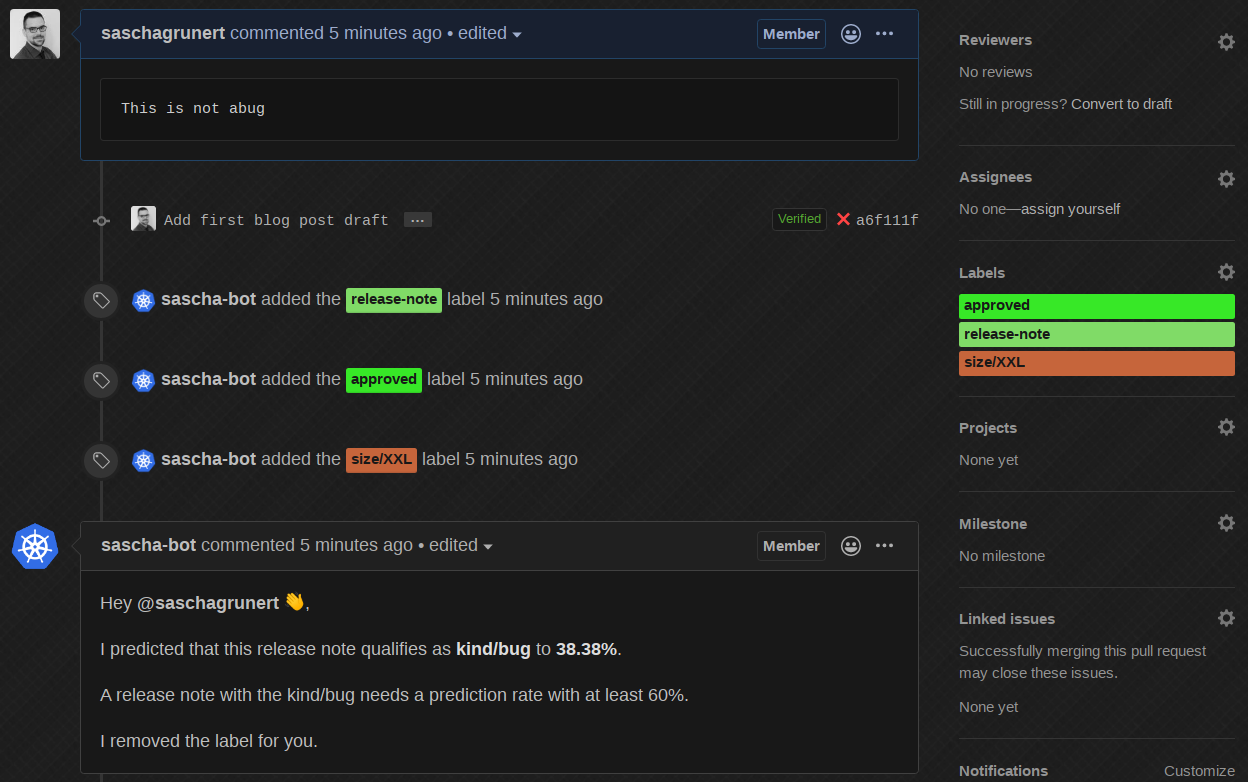
机器人为我们完成了工作,移除了标签并告知我们它做了什么!最后,如果我们将发布说明更改为 None
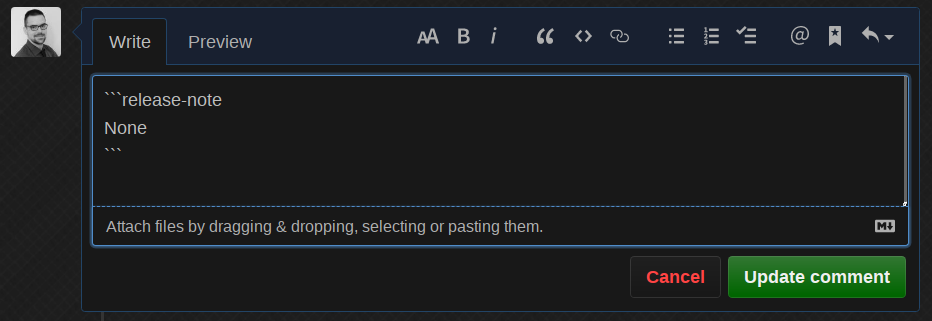
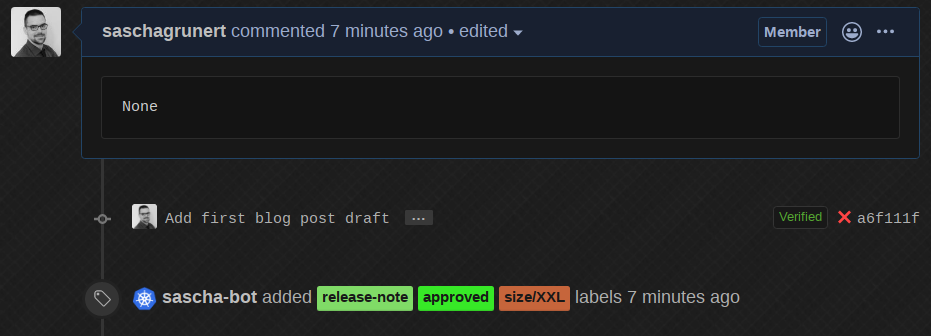
机器人删除了评论,这很好,减少了 PR 上的文本噪音。我演示的所有功能都在一个 Kubernetes 集群中运行,这使得将 kfserving API 公开给公众完全没有必要。这引入了一种间接的 API 速率限制,因为只有通过 Prow 机器人用户才能使用。
如果你想亲自尝试一下,请随时在 kubernetes-analysis 中打开一个 新的测试问题。这之所以有效,是因为我还为问题启用了插件,而不仅仅是为拉取请求。
那么,我们有一个正在运行的 CI 机器人,它能够根据机器学习模型对新的发布说明进行分类。如果该机器人运行在官方的 Kubernetes 仓库中,那么我们就可以手动纠正错误的标签预测。这样,下一次训练迭代就会采纳这些纠正,从而随着时间的推移不断改进模型。一切都完全自动化!
总结
感谢您阅读到这里!这是我的 Kubernetes GitHub 仓库数据科学之旅。还有很多其他可以优化的地方,例如引入更多类别(不仅仅是 kind/bug 或无类别)或者使用 Kubeflow 的 Katib 进行自动超参数调优。如果您有任何问题或建议,请随时与我联系。再见!