本文发表于一年多前。旧文章可能包含过时内容。请检查页面中的信息自发布以来是否已变得不正确。
一个用于编排高可用性应用程序的自定义 Kubernetes 调度器
只要您愿意遵守规则,在 Kubernetes 上部署和空中旅行都可以是相当愉快的体验。大多数情况下,事情都会“按部就班”。然而,如果一个人有兴趣带着一只必须活着的鳄鱼旅行,或者扩展一个必须保持可用的数据库,情况可能会变得更加复杂。甚至为此建造自己的飞机或数据库可能更容易。抛开带着爬行动物旅行不谈,扩展一个高可用有状态系统绝非易事。
扩展任何系统都包含两个主要组件:
- 添加或移除系统将运行的基础设施,以及
- 确保系统知道如何处理自身被添加和移除的额外实例。
大多数无状态系统,例如 Web 服务器,在创建时不需要知道它们的对等节点。而有状态系统,包括像 CockroachDB 这样的数据库,必须与其对等实例协调并重新分配数据。幸运的是,CockroachDB 负责数据重新分配和复制。棘手的部分是如何在这些操作过程中容忍故障,通过确保数据和实例分布在多个故障域(可用区)中来实现。
Kubernetes 的职责之一是将“资源”(例如磁盘或容器)放入集群中并满足它们所请求的约束。例如:“我必须在可用区 *A* 中”(请参阅 在多个区域中运行),或者“我不能与此 Pod 放置在同一节点上”(请参阅 亲和性和反亲和性)。
除了这些约束之外,Kubernetes 还提供了 StatefulSet,它为 Pod 提供身份以及“跟随”这些已识别 Pod 的持久存储。StatefulSet 中的身份通过 Pod 名称末尾递增的整数来处理。需要注意的是,这个整数必须始终是连续的:在一个 StatefulSet 中,如果 Pod 1 和 3 存在,那么 Pod 2 也必须存在。
在底层,CockroachCloud 将 CockroachDB 的每个区域作为其自己的 Kubernetes 集群中的 StatefulSet 进行部署——请参阅 在单个 Kubernetes 集群中编排 CockroachDB。在本文中,我将关注一个独立的区域、一个 StatefulSet 和一个分布在至少三个可用区中的 Kubernetes 集群。
一个三节点的 CockroachCloud 集群看起来会是这样

在向集群添加额外资源时,我们也会将它们分布到不同的区域。为了获得最快的用户体验,我们同时添加所有 Kubernetes 节点,然后扩充 StatefulSet。
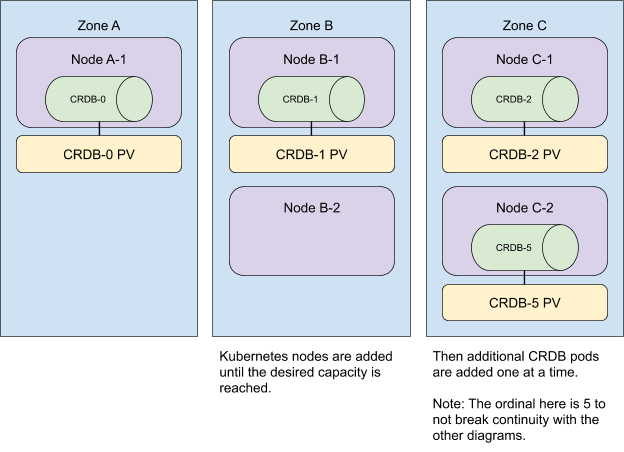
请注意,无论 Pod 分配到 Kubernetes 节点的顺序如何,反亲和性都会得到满足。在示例中,Pod 0、1 和 2 分别被分配到区域 A、B 和 C,但 Pod 3 和 4 以不同的顺序,分别被分配到区域 B 和 A。反亲和性仍然得到满足,因为这些 Pod 仍然放置在不同的区域中。
要从集群中移除资源,我们以相反的顺序执行这些操作。
我们首先缩减 StatefulSet,然后从集群中移除所有没有 CockroachDB Pod 的节点。
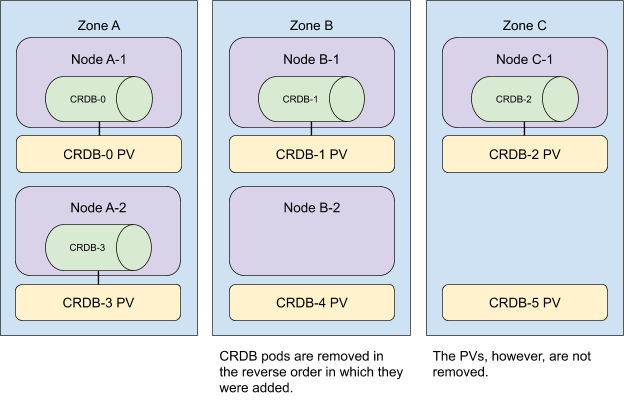
现在,请记住,大小为 *n* 的 StatefulSet 中的 Pod 必须具有范围 `[0,n)` 内的 ID。当 StatefulSet 缩容 *m* 个 Pod 时,Kubernetes 会从最高序数开始,向最低序数移除 *m* 个 Pod,与它们添加时的顺序相反。考虑下面的集群拓扑

当序数 5 到 3 从此集群中移除时,StatefulSet 仍会存在于所有 3 个可用区中。
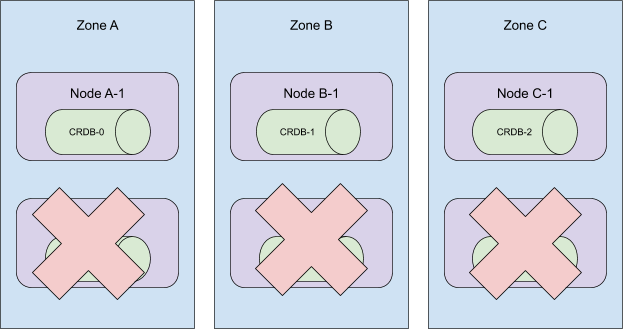
然而,Kubernetes 的调度器并不 *保证* 上述放置,正如我们最初预期的那样。
我们对以下方面的综合知识导致了这种误解。
- Kubernetes 自动将 Pods 分散到不同区域 的能力
- 当 Pod 部署时,一个具有 *n* 个副本的 StatefulSet 会按 ` {0..n-1} ` 的顺序依次创建 Pod 的行为。有关更多详细信息,请参阅 StatefulSet。
考虑以下拓扑
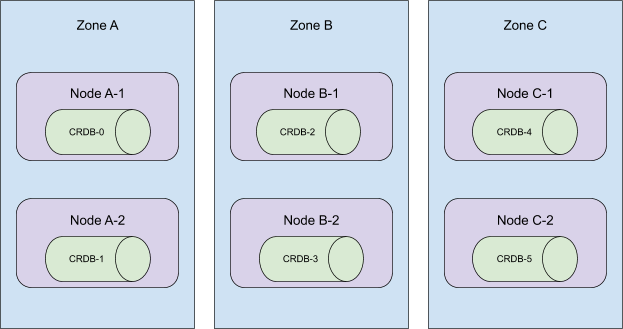
这些 Pod 是按顺序创建的,并分布在集群的所有可用区中。当序数 5 到 3 被终止时,这个集群将失去在区域 C 的存在!
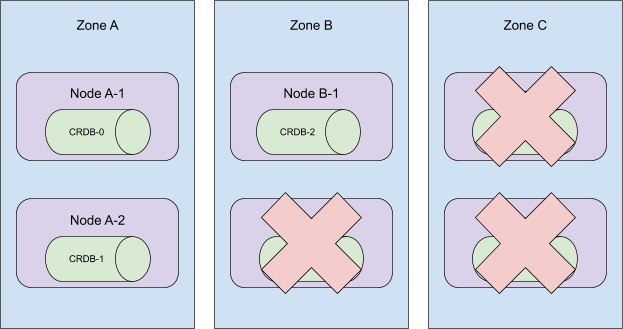
更糟糕的是,当时我们的自动化会移除节点 A-2、B-2 和 C-2。这使得 CRDB-1 处于未调度状态,因为持久卷只能在其最初创建的区域中使用。
为了纠正后一个问题,我们现在采用“逐个搜寻”的方法来从集群中移除机器。不再盲目地从集群中移除 Kubernetes 节点,而是只移除没有 CockroachDB Pod 的节点。更艰巨的任务是驾驭 Kubernetes 调度器。
一次头脑风暴会议给我们留下了 3 个选择
1. 升级到 Kubernetes 1.18 并利用 Pod 拓扑散布约束。
虽然这看起来可能是一个完美的解决方案,但在撰写本文时,Kubernetes 1.18 在公共云中最常见的两个托管 Kubernetes 服务 EKS 和 GKE 上尚不可用。此外,Pod 拓扑散布约束 在 1.18 中仍然是一个 Beta 功能,这意味着即使 v1.18 可用,它也不保证在托管集群中可用。整个尝试令人担忧地让人想起在 Internet Explorer 8 仍然存在时查看 caniuse.com。
2. **按区域部署 StatefulSet。**
与其让一个 StatefulSet 分布在所有可用区域,不如为每个区域提供一个具有节点亲和性的 StatefulSet,这样可以手动控制我们的区域拓扑。我们的团队过去曾将此视为一个选项,这使其特别有吸引力。最终,我们决定放弃此选项,因为它将需要对我们的代码库进行大规模改造,并且对现有客户集群进行迁移也将是一项同样浩大的工程。
3. 编写一个自定义的 Kubernetes 调度器。
感谢 Kelsey Hightower 的一个例子和 Banzai Cloud 的一篇博客文章,我们决定深入研究并编写我们自己的 自定义 Kubernetes 调度器。一旦我们的概念验证部署并运行,我们很快发现 Kubernetes 调度器还负责将持久卷映射到它调度的 Pod。 kubectl get events 的输出曾让我们相信有另一个系统在运行。在寻找负责存储声明映射的组件的过程中,我们发现了 kube-scheduler 插件系统。我们的下一个 POC 是一个 `Filter` 插件,它根据 Pod 序数确定适当的可用区,并且它完美无缺地工作!
我们的 自定义调度器插件 是开源的,并在我们所有的 CockroachCloud 集群中运行。控制 StatefulSet Pods 的调度方式让我们能够自信地进行扩展。一旦 Pod 拓扑散布约束在 GKE 和 EKS 中可用,我们可能会考虑淘汰我们的插件,但维护开销出人意料地低。更好的是:插件的实现与我们的业务逻辑正交。部署它或将其淘汰,就像更改 StatefulSet 定义中的 `schedulerName` 字段一样简单。
Chris Seto 是 Cockroach Labs 的软件工程师,负责 CockroachCloud 和 CockroachDB 的 Kubernetes 自动化。