使用 API 流增强 Kubernetes API 服务器效率
高效管理 Kubernetes 集群至关重要,尤其是随着集群规模的不断增长。大型集群面临的一个重大挑战是由 list 请求引起的内存开销。
在现有的实现中,kube-apiserver 处理 list 请求时,会在将任何数据传输给客户端之前,先在内存中组装整个响应。但如果响应体非常大,比如几百兆字节呢?此外,想象一下这样的场景:多个 list 请求同时涌入,可能是在短暂的网络中断之后。虽然 API 优先级和公平性已被证明可以合理地保护 kube-apiserver 免受 CPU 过载的影响,但它对内存保护的影响明显较小。这可以用单个 API 请求对资源消耗的不同性质来解释——CPU 使用率在任何给定时间都受一个常数的限制,而内存是不可压缩的,可以与处理对象的数量成比例增长且无上限。这种情况构成了真正的风险,可能会在几秒钟内因内存不足(OOM)情况而压垮并导致任何 kube-apiserver 崩溃。为了更好地理解这个问题,让我们看看下面的图表。
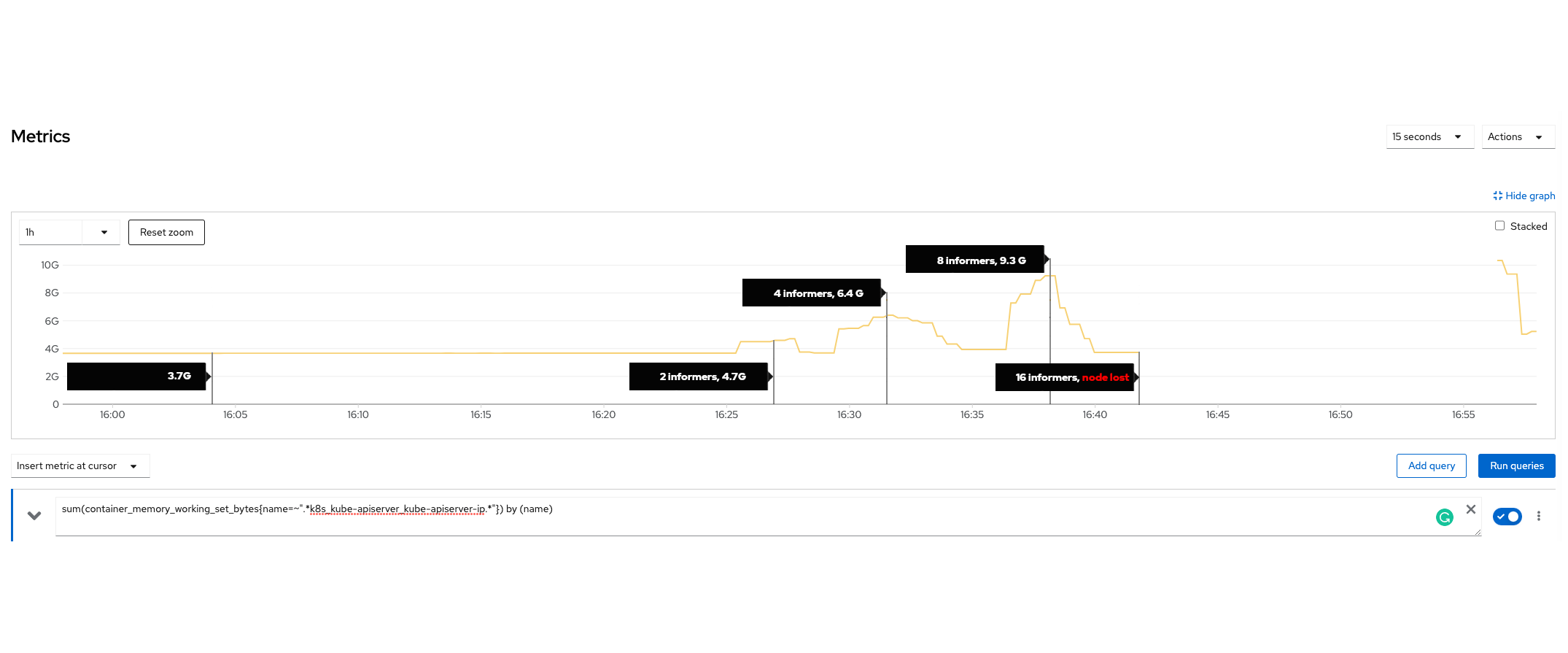
该图显示了 kube-apiserver 在一次综合测试期间的内存使用情况。(更多细节请参见综合测试部分)。结果清楚地表明,增加 Informer 的数量会显著增加服务器的内存消耗。值得注意的是,在大约 16:40,服务器在仅服务 16 个 Informer 时就崩溃了。
为什么 kube-apiserver 会为 list 请求分配如此多的内存?
我们的调查发现,这种大量的内存分配是因为服务器在向客户端发送第一个字节之前必须:
- 从数据库中获取数据,
- 将数据从其存储格式反序列化,
- 最后,通过将数据转换并序列化为客户端请求的格式来构建最终响应。
这一系列操作导致了大量的临时内存消耗。实际使用量取决于许多因素,如页面大小、应用的过滤器(例如标签选择器)、查询参数以及单个对象的大小。
不幸的是,无论是 API 优先级和公平性、Golang 的垃圾回收,还是 Golang 的内存限制,都无法防止系统在这种情况下耗尽内存。内存会突然且迅速地被分配,仅仅几个请求就可能迅速耗尽可用内存,导致资源枯竭。
根据 API 服务器在节点上的运行方式,它可能因在这些不受控制的峰值期间超出配置的内存限制而被内核通过 OOM 杀死,或者如果没有配置限制,它可能对控制平面节点产生更坏的影响。最糟糕的是,在第一个 API 服务器出现故障后,相同的请求很可能会命中高可用性设置中的另一个控制平面节点,并可能产生相同的影响。这可能是一种难以诊断和恢复的情况。
流式 list 请求
今天,我们激动地宣布一项重大改进。随着 watch list 功能在 Kubernetes 1.32 中升级到 Beta 版,client-go 用户可以通过将 list 请求切换为(一种特殊的)watch 请求来选择性加入(在明确启用 WatchListClient 特性门控后)流式列表。
Watch 请求由 watch cache 提供服务,这是一个旨在提高读取操作可伸缩性的内存缓存。通过单独流式传输每个项目而不是返回整个集合,新方法保持了恒定的内存开销。API 服务器受 etcd 中允许的单个对象最大大小加上一些额外分配的限制。与传统的 list 请求相比,这种方法极大地减少了临时内存使用,确保了系统更高效、更稳定,尤其是在给定类型的对象数量众多或平均对象较大的集群中,尽管使用了分页,内存消耗仍然很高。
基于从综合测试中获得的见解(见综合测试),我们开发了一个自动化的性能测试,以系统地评估 watch list 功能的影响。这个测试复制了相同的场景,生成大量带有大负载的 Secret,并扩展 Informer 的数量来模拟繁重的 list 请求模式。自动化测试会定期执行,以监控在启用和禁用该功能时服务器的内存使用情况。
结果显示,启用 watch list 功能后有了显著的改进。当该功能开启时,kube-apiserver 的内存消耗稳定在大约 2 GB。相比之下,当该功能禁用时,内存使用量增加到大约 20 GB,增长了 10 倍!这些结果证实了新的流式 API 的有效性,它减少了临时内存占用。
为你的组件启用 API 流式传输
升级到 Kubernetes 1.32。确保你的集群使用 etcd 3.4.31+ 或 3.5.13+ 版本。更改你的客户端软件以使用 watch list。如果你的客户端代码是用 Golang 编写的,你需要为 client-go 启用 WatchListClient。有关启用该功能的详细信息,请阅读为 Client-Go 引入特性门控:增强灵活性和控制力。
接下来是什么?
在 Kubernetes 1.32 中,该功能在 kube-controller-manager 中默认启用,尽管它仍处于 Beta 状态。这将最终扩展到其他核心组件,如 kube-scheduler 或 kubelet;一旦该功能普遍可用,如果不是更早的话。我们鼓励其他第三方组件在 Beta 阶段选择加入该功能,尤其是当它们有可能访问大量资源或具有潜在大型对象的类型时。
目前,API 优先级和公平性为 list 请求分配了一个合理的小成本。这是必要的,以便为 list 请求足够廉价的平均情况提供足够的并行性。但这与许多大型对象的突发异常情况不匹配。一旦 Kubernetes 生态系统的大部分切换到 watch list,list 成本估算可以改为更大的值,而不会在平均情况下降低性能,从而增加对未来可能仍然会冲击 API 服务器的这类请求的保护。
综合测试
为了重现这个问题,我们进行了一项手动测试,以了解 list 请求对 kube-apiserver 内存使用的影响。在测试中,我们创建了 400 个 Secret,每个包含 1MB 的数据,并使用 Informer 来检索所有 Secret。
结果令人震惊,仅 16 个 Informer 就足以导致测试服务器内存耗尽并崩溃,这表明在这种情况下内存消耗会多么迅速地增长。
特别感谢 @deads2k 在塑造此功能方面的帮助。
Kubernetes 1.33 更新
自从这个功能启动以来,Marek Siarkowicz 将一项新技术集成到了 Kubernetes API 服务器中:流式集合编码。Kubernetes v1.33 引入了两个相关的特性门控,StreamingCollectionEncodingToJSON 和 StreamingCollectionEncodingToProtobuf。这些功能通过流进行编码,避免一次性分配所有内存。此功能与现有的 list 编码逐位兼容,能节省更多服务器端内存,且无需对客户端代码进行任何更改。在 1.33 中,WatchList 特性门控默认是禁用的。