Kubernetes v1.33:流式 List 响应
随着基础设施的增长,管理 Kubernetes 集群的稳定性变得越来越重要。在大规模集群运营中最具挑战性的方面之一,是处理获取大量数据集的列表(List)请求——这是一个常见的操作,可能会意外地影响集群的稳定性。
今天,Kubernetes 社区激动地宣布一项重大的架构改进:列表响应的流式编码。
问题:大型资源导致不必要的内存消耗
当前的 API 响应编码器只是将整个响应序列化到一个连续的内存中,并执行一次 ResponseWriter.Write 调用将数据传输给客户端。尽管 HTTP/2 能够将响应分割成更小的帧进行传输,但底层的 HTTP 服务器仍然将完整的响应数据作为一个单一的缓冲区持有。即使单个帧被传输给客户端,与这些帧相关的内存也无法增量释放。
当集群规模扩大时,单个响应体可能会非常大——比如达到数百兆字节。在大规模场景下,当前的方法变得尤其低效,因为它在传输过程中阻止了内存的增量释放。想象一下,当发生网络拥塞时,那个大型响应体的内存块会持续活跃数十秒甚至数分钟。这个限制导致 kube-apiserver 进程中不必要地高且持久的内存消耗。如果同时发生多个大型列表请求,累积的内存消耗会迅速升级,可能导致内存不足(OOM)的情况,从而危及集群的稳定性。
encoding/json 包使用 sync.Pool 来复用序列化过程中的内存缓冲区。虽然这对于一致的工作负载是高效的,但这种机制在处理偶发的大型列表响应时会产生挑战。当处理这些大型响应时,内存池会显著扩张。但由于 sync.Pool 的设计,这些过大的缓冲区在使用后仍然被保留。随后的较小列表请求会继续利用这些大型内存分配,从而阻止了垃圾回收,并导致即使在初始的大型响应完成后,kube-apiserver 的内存消耗仍然居高不下。
此外,Protocol Buffers 并非为处理大型数据集而设计。但它非常适合处理大型数据集中的**单个**消息。这凸显了需要基于流的方法,这种方法可以增量地处理和传输大型集合,而不是作为单一的整体块。
作为一般经验法则,如果您处理的消息每个都超过一兆字节,那么可能是时候考虑一种替代策略了。
列表响应的流式编码器
流式编码机制专为列表响应设计,利用了它们常见的、定义良好的集合结构。其核心思想只专注于集合结构中的 **Items** 字段,该字段在大型响应中占用了大部分内存。新的流式编码器不是将整个 **Items** 数组编码为一个连续的内存块,而是单独处理和传输每一项,从而允许在帧或块传输时逐步释放内存。因此,逐个编码项可以显著减少 API 服务器所需的内存占用。
由于 Kubernetes 对象通常被限制在 1.5 MiB(来自 ETCD),流式编码使得内存消耗保持可预测和可管理,无论列表响应中有多少对象。其结果是 API 服务器的稳定性显著提高,内存峰值减少,以及整体集群性能得到改善——尤其是在可能同时发生多个大型列表操作的环境中。
为了确保完美的向后兼容性,流式编码器在激活前会严格验证 Go 结构体标签,保证与原始编码器实现字节对字节的一致性。标准编码机制处理除 **Items** 之外的所有字段,从而在整个过程中保持相同的输出格式。这种方法无缝支持所有 Kubernetes 列表类型——从内置的 **\*List** 对象到自定义资源的 **UnstructuredList** 对象——无需任何客户端修改,也无需客户端知晓底层的编码方法已经改变。
您会注意到的性能提升
- 减少内存消耗: 在处理大型**列表**请求时,显著降低了 API 服务器的内存占用,尤其是在处理**大型资源**时。
- 提高可扩展性: 使 API 服务器能够处理更多的并发请求和更大的数据集,而不会耗尽内存。
- 增强稳定性: 降低了因内存不足(OOM)而被终止以及服务中断的风险。
- 高效的资源利用: 优化了内存使用,提高了整体资源效率。
基准测试结果
为了验证结果,Kubernetes 引入了一个新的**列表**基准测试,该测试并发执行 10 个**列表**请求,每个请求返回 1GB 的数据。
基准测试显示性能提高了 20 倍,内存使用量从 70-80GB 减少到 3GB。
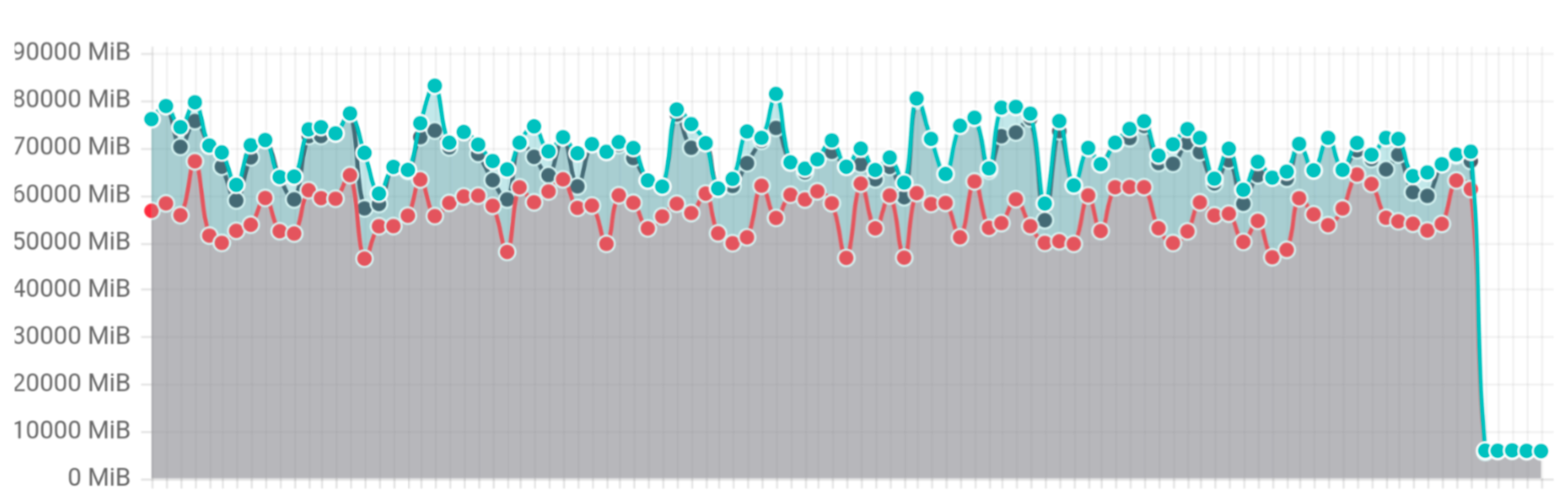
列表基准测试内存使用情况